Renderowanie po stronie serwera (SSR) zyskuje coraz większe znaczenie w ciągle ewoluującym świecie front-endu. Większość frameworków oferuje już własne, „meta” warianty ukierunkowane na SSR, jak Next.js dla Reacta, Nuxt dla Vue i SvelteKit dla Svelte. Społeczność Angulara stworzyła Analog.js, aby wypełnić tę lukę, ale natywne rozwiązanie na pewien czas zostało nieco w tyle. Ostatnie wersje pokazują jednak, że zespół Angulara ponownie mocno skupił się na tym obszarze, wprowadzając nowe funkcje, lepszą wydajność i bardziej zaawansowane możliwości. SSR może być potężnym dodatkiem do Twojego zestawu narzędzi. Zanurzmy się więc w temat i zobaczmy, jak działa w Angularze.
Aby przeanalizować temat na praktycznych przykładach, przygotowałem prostą, demonstracyjną aplikację e-commerce. Jeśli chcesz samodzielnie pobawić się SSR, znajdziesz ją tutaj.
Szukasz gotowego do wdrożenia przykładu aplikacji z Angular SSR? Zajrzyj do kodu źródłowego angular.love.
Jak to działa?
Żeby lepiej zrozumieć SSR, przypomnijmy sobie najpierw, jak wygląda proces wyświetlania standardowej aplikacji renderowanej po stronie klienta:
- Przeglądarka pobiera plik HTML (niemal pustą powłokę z elementem app-root) wraz z arkuszami stylów, zasobami i kodem JS z serwera.
- Skrypty są parsowane i uruchamiane: logika Angulara instruuje przeglądarkę, jak zbudować strukturę DOM z komponentów aplikacji.
- Zawartość ekranu zwykle zależy od danych z API, więc przeglądarka wykonuje żądania HTTP i odpowiednio aktualizuje UI.
- Gdy dane zostaną wczytane, a DOM w pełni zbudowany, aplikacja jest gotowa do użycia.
Tak wygląda to, co przeglądarka otrzymuje z serwera w aplikacji renderowanej po stronie klienta:

Teraz rozbijmy na kroki proces wyświetlania aplikacji renderowanej po stronie serwera:
- Przeglądarka pobiera HTML, style i zasoby, ale w odróżnieniu od CSR, ten HTML jest już treściwy i w pełni wyrenderowany.
- Następnie przeglądarka pobiera, parsuje i uruchamia skrypty JS.
- Angular przejmuje kontrolę nad DOM i czyni stronę interaktywną. Ten proces nazywa się hydracją.
W SSR HTML jest renderowany wcześniej, na serwerze, i zawiera kompletną treść zanim trafi do przeglądarki:

Tak wygląda to w karcie podglądu:

Jak zacząć pracę z Angular SSR?
Od wersji 17 Angular CLI po uruchomieniu ng new zapyta, czy włączyć Server-Side Rendering (SSR) i Static Site Generation (SSG) dla nowej aplikacji. Alternatywnie możesz od razu dodać flagę: ng new –ssr.
Jeśli chcesz dodać SSR do istniejącego projektu, uruchom:
ng add @angular/ssr.
Po włączeniu SSR CLI generuje kilka dodatkowych plików. Ich rola w skrócie:
- server.ts – główny punkt wejścia serwera, bootstrapuje aplikację Angulara po stronie serwera. Konfiguruje Express do obsługi żądań i renderowania stron.
- app.config.server.ts – definiuje providery tylko dla serwera i konfiguracje potrzebne do działania SSR.
- app.routes.server.ts – określa tryb renderowania dla routingu.
- main.server.ts – odpowiednik main.ts, ale do inicjalizacji renderowania po stronie serwera.
Dodatkowo w angular.json (lub project.json, jeśli używasz Nx) pojawią się sekcje konfiguracyjne dla buildów serwerowych.
Gratulacje, Twoja aplikacja działa z włączonym SSR i możesz korzystać z jego zalet. A zatem…
Dlaczego używamy Angular SSR?
Przy SSR serwer wysyła początkowy HTML już wyrenderowany, w momencie budowy albo dynamicznie na żądanie użytkownika. Dostarczone skrypty JS nadal zawierają logikę Angulara, która przejmuje kontrolę nad stroną i obsługuje dalsze interakcje w przeglądarce. Od tego momentu aplikacja działa jak standardowa apka Angularowa.
Możesz zapytać: po co ten dodatkowa praca i zwiększanie złożoności? Oto najważniejsze powody:
Wydajność
Parsowanie i uruchamianie JavaScriptu to jedne z najbardziej zasobożernych zadań przeglądarki. W aplikacji CSR przeglądarka dostaje początkowo prawie pusty HTML (użytkownik widzi „pusty ekran”) i musi zbudować całą zawartość od zera. Możesz to zaobserwować w zakładce Performance Chrome DevTools.
Do tego dochodzi czas pobierania skryptów z serwera, w dużej mierze zależny od sieci. Na urządzeniach mobilnych, gdzie ograniczenia sprzętowe i wolniejsze łącza są powszechne, wydajność często spada jeszcze bardziej.
Im dłużej aplikacja pozostaje niewidoczna i niemożliwa do użycia, tym większa szansa, że użytkownik zrezygnuje z jej użycia. Według badań Google, przy wzroście czasu ładowania strony z 1 do 3 sekund prawdopodobieństwo porzucenia aplikacji przez usera rośnie o 32%. To reprezentacja potencjalnych klientów, których możesz stracić.
Jednym z najlepszych sposobów na audyt wydajności Twojej apki jest Lighthouse. To automatyczne narzędzie, które uruchamia serię testów na stronie i generuje raport ze scoringiem dla każdej kategorii i rekomendacjami poprawek.
Lighthouse mierzy m.in.:
- FCP (First Contentful Paint) – czas do pojawienia się pierwszego tekstu/obrazu (cel: < 1,8 s)
- LCP (Largest Contentful Paint) – czas do załadowania największego elementu (cel: < 2,5 s)
- TBT (Total Blocking Time) – czas blokady głównego wątku podczas ładowania (cel: < 0,15 s)
- CLS (Cumulative Layout Shift) – wskaźnik stabilności wizualnej mierzący niespodziewane zmiany w layoucie (cel: < 0,1)
- SI (Speed Index) – jak szybko strona wizualnie się „wypełnia” (cel: < 1,3 s)
To wynik Lighthouse dla aplikacji demo działającej jako CSR:

A tak poprawia się wynik po uruchomieniu aplikacji z SSR. Różnica jest zauważalna nawet przy prostych aplikacjach: im bardziej złożona aplikacja, tym większy zysk z tego usprawnienia.

Jak SSR winduje Twój wynik Lighthouse:
- Szybszy FCP:
Serwer wysyła w pełni wyrenderowany HTML, więc nie trzeba czekać na pobranie, parsowanie i uruchomienie JavaScript aby kontent się wyświetlił – pojawia się on praktycznie od razu.
- Lepszy LCP:
Kluczowe, duże elementy są prerenderowane na serwerze i pojawiają się szybciej niż w przypadku renderowania po stronie klienta.
- Mniejszy TBT:
Hydracja jest lżejsza niż pełne CSR; początkowy HTML parsuje się bez blokowania, a uruchomienie JavaScript jest odroczone i inkrementalne. Dzięki temu główny wątek pozostaje nieblokowany, a aplikacja szybciej staje się gotowa do użycia.
- Lepszy CLS:
Kompletna struktura HTML, wraz ze zdjęciami i blokami kontentu, jest wysyłana z poprawnymi wymiarami. Zapobiega to nieoczekiwanym przeskokom layoutu, zwykle spowodowanym przez późne montowanie komponentów lub opóźnione ładowanie treści.
- Szybszy SI:
Zawartość pojawia się natychmiast i jest stopniowo ulepszana, zamiast renderować się w dużych, opóźnionych partiach. Prowadzi to do szybszego wizualnego ukończenia strony i płynniejszego UX.
SEO (Search Engine Optimization)
SEO to praktyka polegająca na poprawie widoczności strony internetowej oraz jej pozycji w wynikach wyszukiwania poprzez uczynienie jej bardziej atrakcyjną i dostępną dla wyszukiwarek. Ponieważ wyszukiwarki pełnią rolę bramy do informacji, jeśli Twoja witryna nie pojawia się na szczycie wyników, tracisz większość potencjalnych użytkowników, którzy mogliby być zainteresowani Twoimi treściami, produktami lub usługami.
Boty wyszukiwarek mają trudności z obsługą stron opartych na JavaScripcie, renderowanych po stronie klienta, gdzie cała zawartość jest ładowana dynamicznie dopiero po dostarczeniu początkowego pliku HTML. Nawet jeśli Twoja aplikacja jest świetnie zoptymalizowana i dla użytkownika działa natychmiast, może okazać się zbyt wolna dla bota, który widzi jedynie element główny (root) i kilka odwołań do skryptów. Choć wyszukiwarka Google z biegiem lat znacznie poprawiła indeksowanie treści opartych na JS, proces ten nadal jest powolny. Inne duże wyszukiwarki mają w tym zakresie jeszcze większe ograniczenia. Dlatego tak ważne jest, aby już w początkowej odpowiedzi serwera dostarczać bogaty, wypełniony treścią HTML.
Google wykorzystuje Core Web Vitals jako czynnik rankingowy, dlatego wyższe wyniki w zakresie FCP, LCP i CLS bezpośrednio poprawiają widoczność strony w wynikach wyszukiwania. Podejście mobile-first indexing faworyzuje strony, które ładują się szybko i zapewniają stabilny układ na urządzeniach mobilnych, co sprawia, że korzyści płynące z SSR są w tym kontekście jeszcze bardziej znaczące.
Równie ważne są szybkość i efektywność procesu indeksowania. Wykorzystanie SSR eliminuje wąskie gardło, ponieważ treść nadająca się do zaindeksowania jest dostępna już w początkowej odpowiedzi serwera. Skutkuje to szybszymi cyklami indeksowania, lepszym wskaźnikiem świeżości treści oraz większą widocznością, zwłaszcza w przypadku często aktualizowanych stron.
SSR zapewnia, że pełna struktura witryny jest widoczna dla wyszukiwarek. Wszystkie elementy, takie jak linkowanie wewnętrzne, hierarchia nawigacji czy breadcrumbs, są obecne, co ułatwia zrozumienie struktury oraz relacji wewnętrznych w obrębie strony.
Metadane i Social Media (SMO)
Metadane dostarczają kluczowych informacji o zawartości strony internetowej, takich jak tytuł, opis, obraz czy słowa kluczowe jeszcze zanim strona zostanie w pełni załadowana. Podczas gdy aplikacje CSR zazwyczaj dostarczają ogólne informacje, które nie odzwierciedlają faktycznej, dynamicznie generowanej treści, aplikacja SSR może już w początkowej odpowiedzi zdefiniować dokładne metadane oparte na rzeczywistej zawartości strony.
Przeglądarki wykorzystują metadane w celu ulepszenia doświadczenia użytkownika. Na przykład tytuł strony pojawia się w kartach przeglądarki, zakładkach oraz w historii, natomiast meta description wpływa na to, jak strona jest prezentowana w wynikach wyszukiwania.
Platformy mediów społecznościowych również opierają się na metadanych. Ich crawlery pobierają udostępniony adres URL, analizują odpowiedź HTML i wyszukują określone metadane w sekcji <head>, aby wygenerować bogate podglądy linków. Ponieważ crawlery te z reguły nie potrafią uruchomić kodu JavaScript, metadane muszą znajdować się już w początkowej odpowiedzi serwera. Wysokiej jakości i dokładne podglądy zwiększają wskaźniki zaangażowania, ponieważ użytkownicy chętniej klikają w linki, które oferują jasny i atrakcyjny podgląd zawartości.
Tagi Open Graph, pierwotnie opracowane przez Facebooka, a dziś szeroko stosowane również na platformach takich jak LinkedIn, WhatsApp czy Slack, wykorzystują właściwości takie jak og:title, og:description, og:image oraz og:url, aby określić, w jaki sposób treść ma być wyświetlana w kanałach społecznościowych.
Twitter Cards działają w podobny sposób, ale korzystają ze specjalnych tagów dla Twittera, takich jak twitter:card, twitter:title i twitter:image, aby optymalizować zawartość pod kątem tej platformy. Twitter oferuje różne typy kart, m.in. summary cards, large image cards oraz app cards.
Poza mediami społecznościowymi, te tagi są coraz częściej wykorzystywane również przez komunikatory, klientów poczty e-mail oraz inne platformy do generowania podglądów linków. Dzięki temu stanowią one istotny element marketingu treści i spójności marki w całym ekosystemie społecznościowym sieci.

Canonical URL to meta tag, który informuje wyszukiwarki, która wersja strony internetowej powinna być uznana za „oficjalną” lub główną, gdy wiele adresów URL zawiera identyczną lub bardzo podobną treść. Pomaga to rozwiązać problemy z duplikacją treści, które mogą negatywnie wpływać na pozycję w wynikach wyszukiwania, na przykład wtedy, gdy ta sama strona jest dostępna pod różnymi adresami. Konsolidując wartość SEO w jednym, preferowanym adresie URL, tagi kanoniczne pomagają utrzymać autorytet pozycji w wyszukiwarce, zapobiegają kanibalizacji słów kluczowych oraz zapewniają, że wyszukiwarki indeksują i wyświetlają właściwą, zamierzoną wersję każdej strony.
Aby lepiej wyjaśnić to zagadnienie, przygotowałem prosty serwis SEO, który aktualizuje metadane.
@Injectable({ providedIn: 'root' })
export class SeoService {
private readonly _titleService = inject(Title);
private readonly _metaService = inject(Meta);
private readonly _document = inject(DOCUMENT);
setSeoData(seoData: SeoData): void {
const title = seoData.title ? `${seoData.title} | SSRmart` : 'SSRmart';
this._titleService.setTitle(title);
this._updateMetaTag('og:title', title);
this._updateMetaTag('og:description', seoData.description);
this._updateMetaTag('og:image', this._getImageParamsUrl(seoData.imageUrl));
this._updateMetaTag('og:url', seoData.url);
this._updateMetaTag('og:type', seoData.type);
this._updateMetaTag('twitter:card', 'summary_large_image');
this._updateMetaTag('twitter:title', title);
this._updateMetaTag('twitter:description', seoData.description);
this._updateMetaTag(
'twitter:image',
this._getImageParamsUrl(seoData.imageUrl)
);
this._updateMetaTag(
'robots',
seoData.noIndex ? 'noindex,nofollow' : 'index,follow'
);
this._updateCanonicalUrl(seoData.url);
}
private _updateMetaTag(name: string, content?: string): void {
if (!content) {
this._metaService.removeTag(`property="${name}"`);
return;
}
if (this._metaService.getTag(`property="${name}"`)) {
this._metaService.updateTag({ property: name, content });
} else {
this._metaService.addTag({ property: name, content });
}
}
private _updateCanonicalUrl(url?: string): void {
const existingCanonicalUrl = this._document.querySelector(
'link[rel="canonical"]'
);
if (existingCanonicalUrl) existingCanonicalUrl.remove();
if (url) {
const canonicalLink = this._document.createElement('link');
canonicalLink.rel = 'canonical';
canonicalLink.href = url;
this._document.head.appendChild(canonicalLink);
}
}
private _getImageParamsUrl(imageUrl?: string): string | undefined {
if (!imageUrl) return undefined;
/*
Open Graph image requirements:
- size: 1200x630
- format: jpg or png
*/
const url = new URL(imageUrl);
url.search = '';
url.searchParams.set('w', '1200');
url.searchParams.set('fm', 'jpg');
url.searchParams.set('fit', 'crop');
return url.toString();
}
}Ten serwis jest następnie zasilany danymi SeoData, które można skonfigurować za pomocą route resolvers. Może to być proste mapowanie pobranych właściwości, na przykład na stronie szczegółów produktu, lub znacznie bardziej szczegółowa konfiguracja, wykorzystująca dowolną liczbę właściwości, jak w przypadku strony wyników wyszukiwania produktów.
const getTitle = (
category: string,
searchTerm: string,
isBestSeller: boolean
): string => {
if (categoryTypeGuard(category)) {
return searchTerm
? `Search Results for "${searchTerm}" in ${capitalize(category)}`
: `${capitalize(category)} Products`;
}
if (searchTerm) return `Search Results for "${searchTerm}"`;
if (isBestSeller) return 'Best Selling Products';
return 'Products';
};
const getDescription = (
category: string,
searchTerm: string,
isBestSeller: boolean
): string => {
if (searchTerm) return `Find the best products matching "${searchTerm}".`;
if (categoryTypeGuard(category))
return `Discover amazing ${category} products at great prices.`;
if (isBestSeller) return 'Shop our most popular and best-selling products.';
return 'Browse our wide selection of products.';
};
export const productSearchSeoResolver: ResolveFn<SeoData> = (route) => {
const category = route.params['category'];
const searchTerm = route.queryParams['term'];
const isBestSeller = route.queryParams['bestsellers'];
const baseUrl = inject(ConfigService).get('baseUrl');
const url = category
? `${baseUrl}/products/${category}`
: `${baseUrl}/products`;
const imageUrl =
'https://images.unsplash.com/photo-1498049794561-7780e7231661';
return {
title: getTitle(category, searchTerm, Boolean(isBestSeller)),
description: getDescription(category, searchTerm, Boolean(isBestSeller)),
keywords: ['products', 'shop', 'online store', category, searchTerm].filter(
Boolean
),
type: 'website',
url,
imageUrl,
};
};Aby sprawdzić, jak działają podglądy oparte na metadanych, możesz skorzystać z różnych narzędzi, takich jak Facebook Sharing Debugger. Narzędzie to pokazuje podgląd, który pojawiłby się po udostępnieniu linku, wyświetla wykryte metadane oraz ostrzega o wszelkich brakujących informacjach. Poniżej znajduje się wynik dla jednej ze stron produktów:
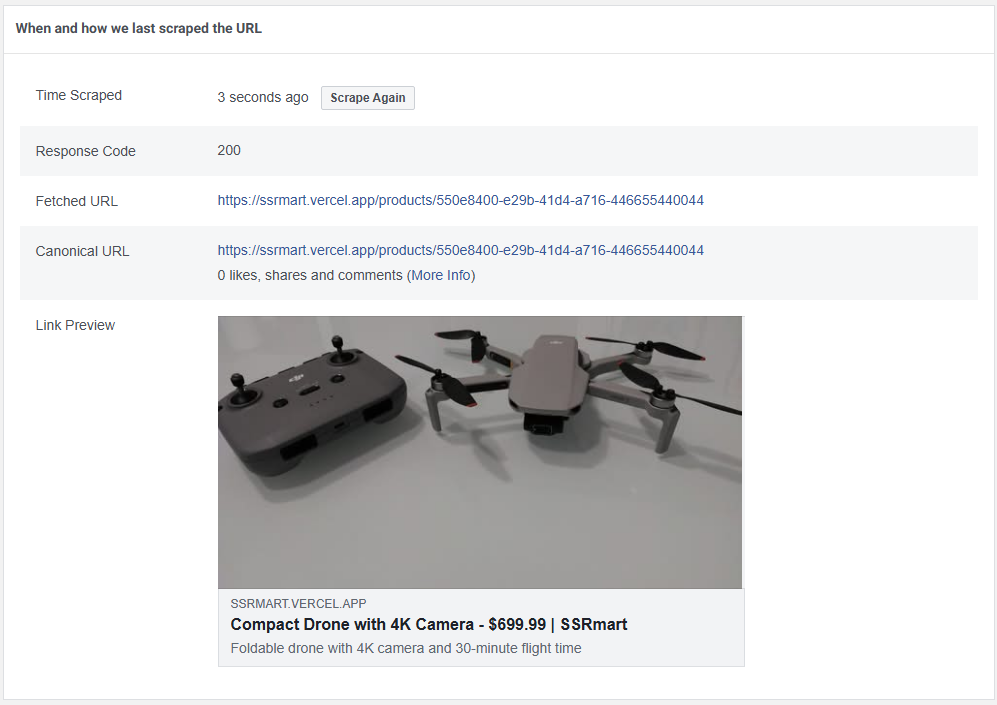
Dane strukturalne (Structured Data) z JSON-LD
To kolejna metoda dodawania semantycznego oznaczenia do stron internetowych, która pomaga wyszukiwarkom skuteczniej rozumieć i kategoryzować treści, często prowadząc do rozszerzonych wyników wyszukiwania. To rozwiązanie wykorzystuje osobny blok skryptu w sekcji <head> strony, dzięki czemu można ją łatwo zaimplementować bez zaśmiecania struktury dokumentu. Zgodnie ze standardami Schema.org, JSON-LD (JavaScript Object Notation for Linked Data) może opisywać różne typy treści przy użyciu ustandaryzowanych właściwości, takich jak @type, name, description, image, rating czy price (na przykład w kontekście aplikacji e-commerce). JSON-LD stał się preferowaną metodą implementacji danych strukturalnych ze względu na swoją elastyczność, łatwość utrzymania oraz wyraźne zalecenie Google dotyczące jego stosowania.
Poniżej znajduje się utility function, która generuje dane strukturalne produktu na podstawie jego konfiguracji, pobranej za pośrednictwem resolvera:
export const generateProductStructuredData = (
product: Product,
baseUrl: string
): StructuredData => {
return {
'@context': 'https://schema.org/',
'@type': 'Product',
'@id': `${baseUrl}/products/${product.id}`,
name: product.name,
description: product.shortDescription,
image: product.imageUrl,
sku: product.id,
category: product.category,
keywords: product.keywords.join(', '),
aggregateRating: {
'@type': 'AggregateRating',
ratingValue: product.rating,
ratingCount: product.ratingCount,
bestRating: '5',
worstRating: '1',
},
offers: {
'@type': 'Offer',
url: `${baseUrl}/products/${product.id}`,
priceCurrency: 'USD',
price: product.price,
itemCondition: 'https://schema.org/NewCondition',
availability: 'https://schema.org/InStock',
seller: {
'@type': 'Organization',
name: 'SSRMart',
url: baseUrl,
},
},
brand: {
'@type': 'Brand',
name: 'SSRMart',
},
additionalProperty: [
{
'@type': 'PropertyValue',
name: 'Best Seller',
value: product.isBestSeller,
},
],
};
};
Powstałe dane przekazywane są do StructuredDataService, który wstawia odpowiedni skrypt do <head>:
@Injectable({ providedIn: 'root' })
export class StructuredDataService {
private readonly _document = inject(DOCUMENT);
addStructuredData(data: StructuredData, id: StructuredDataId): void {
const script = this._document.createElement('script');
script.type = 'application/ld+json';
script.textContent = JSON.stringify(data);
script.id = this._transformId(id);
this.removeStructuredData(id);
this._document.head.appendChild(script);
}
removeStructuredData(id: string): void {
const script = this._document.getElementById(this._transformId(id));
if (script) {
script.remove();
}
}
private _transformId(id: string): string {
return `${id}-structured-data`;
}
}
Aby zweryfikować wyniki, używam narzędzia Rich Results Test. Google opiera się na danych strukturalnych, aby zrozumieć zawartość strony i wyświetlać ją w wynikach wyszukiwania w bogatszej formie. Aby Twoja witryna kwalifikowała się do wyświetlania jako jeden z takich rozszerzonych wyników, postępuj zgodnie z tym przewodnikiem.
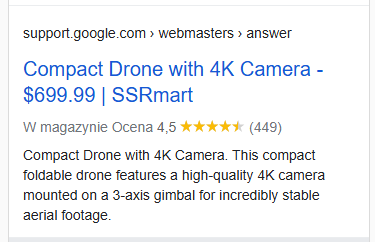
Indeksowanie stron
Indeksowanie stron (page indexing) to proces, w którym wyszukiwarki odkrywają, analizują i zapisują strony internetowe w swoich bazach danych, aby mogły one zostać odnalezione i wyświetlone w wynikach wyszukiwania, gdy użytkownicy wpisują odpowiednie zapytania.
Sitemap
Mapa witryny (sitemap) dostarcza wyszukiwarkom mapy drogowej zawartości strony internetowej, dzięki czemu mogą one skuteczniej odkrywać, przeszukiwać (crawlować) i indeksować jej treści. Zazwyczaj jest to dokument w formacie XML, który definiuje metadane takie jak:
- Kanoniczny adres URL lokalizacji strony
- Data ostatniej modyfikacji
- Częstotliwość zmian treści (np. codziennie, co tydzień, co miesiąc itp.)
- Względne znaczenie poszczególnych stron w obrębie witryny
export const sitemapRoute = (router: Router): void => {
router.get('/sitemap.xml', async (req, res) => {
const { baseUrl } = getServerConfig();
const sitemapItems = await getSitemapItems(baseUrl);
const xml = `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
${sitemapItems
.map(
(item) => `
<url>
<loc>${item.loc}</loc>
<lastmod>${item.lastmod}</lastmod>
<changefreq>${item.changefreq}</changefreq>
<priority>${item.priority}</priority>
</url>`
)
.join('')}
</urlset>`;
res.set('Content-Type', 'application/xml');
res.set('Cache-Control', 'public, max-age=86400, s-maxage=86400');
res.send(xml);
});
};
Pomaga to zwiększyć szybkość indeksowania, dzięki czemu opublikowane lub zmodyfikowane treści mogą być szybciej odkrywane i przetwarzane przez wyszukiwarki.
Aby uzyskać najlepszy efekt SEO, mapa witryny powinna zawierać wyłącznie kanoniczne adresy URL oraz strony, które mają być indeksowane, z pominięciem zduplikowanej treści oraz stron zablokowanych przez plik robots.txt.
Robots.txt
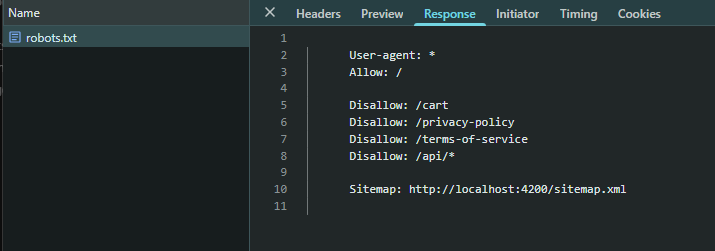
Robots.txt to plik tekstowy umieszczony w katalogu głównym witryny, zawierający instrukcje dla robotów wyszukiwarek dotyczące tego, które części aplikacji mogą, a których nie powinny przeszukiwać. Używa prostych komend, takich jak:
- User-agent: określa, do którego robota wyszukiwarki odnoszą się zasady
- Disallow: blokuje dostęp do określonych stron lub katalogów
- Allow: zezwala na dostęp do wybranych zasobów
Plik ten pomaga zarządzać budżetem indeksowania (crawl budget), zapobiegając marnowaniu zasobów wyszukiwarek na nieistotne strony, zduplikowaną treść lub środowiska testowe. Dodatkowo zapewnia kontrolę nad treściami, umożliwiając blokowanie dostępu do obszarów wrażliwych.
Meta robots
Możesz jawnie poinstruować wyszukiwarki, aby nie uwzględniały określonej strony w wynikach wyszukiwania, nawet jeśli mogą ją przeszukiwać i uzyskiwać dostęp do jej treści, poprzez zdefiniowanie meta tagu noindex. Oznacza to, że wyszukiwarki wciąż mogą śledzić linki znajdujące się na stronach oznaczonych jako noindex, aby odkrywać inne treści, jednak sama strona noindex nie pojawi się w wynikach wyszukiwania. Pomaga to poprawić ogólną jakość witryny, zapobiegając sytuacjom, w których strony o niskiej wartości konkurują w wynikach wyszukiwania z Twoimi kluczowymi i ważnymi treściami.
Tryby renderowania
Jak wspomniano wcześniej, plik app.routes.server.ts zawiera konfigurację ścieżek serwera. Jego głównym zadaniem jest określenie trybu renderowania dla poszczególnych ścieżek w aplikacji. Angular oferuje trzy tryby renderowania:
- Server (SSR) – serwer renderuje stronę przy każdym żądaniu i odsyła do przeglądarki w pełni wypełniony kod HTML,
- Prerender (SSG) – strona jest renderowana w czasie budowania aplikacji, dzięki czemu można serwować statyczny plik HTML,
- Client (CSR) – renderowanie odbywa się po stronie przeglądarki (domyślne zachowanie Angulara).
export const serverRoutes: ServerRoute[] = [
{
path: '',
renderMode: RenderMode.Server,
},
{
path: 'products',
renderMode: RenderMode.Server,
},
{
path: 'privacy-policy',
renderMode: RenderMode.Prerender,
},
...,
{
path: '**',
renderMode: RenderMode.Server,
},
];Każdy tryb renderowania ma swoje zalety i wady, dlatego należy go wybierać w zależności od konkretnych potrzeb Twojej aplikacji. Przyjrzyjmy się bliżej każdemu z nich.
SSR (Server-Side Rendering)
Jak wspomniano wcześniej w tym artykule, w przypadku Server-Side Rendering (SSR) serwer wysyła do przeglądarki w pełni wyrenderowany dokument HTML. Oznacza to, że przeglądarka nie musi czekać na pobranie i wykonanie kodu JavaScript, zanim wyświetli zawartość strony. Zamiast tego użytkownik natychmiast otrzymuje gotową do wyświetlenia stronę wraz ze wszystkimi niezbędnymi danymi. Takie podejście nie tylko poprawia postrzeganą wydajność aplikacji, ale jest również bardzo korzystne z punktu widzenia SEO, ponieważ wyszukiwarki mogą łatwo przeszukiwać i indeksować w pełni wyrenderowaną zawartość HTML, bez konieczności uruchamiania kodu JavaScript.
Jeśli zdecydujesz się na użycie SSR, pamiętaj, że Twój kod nie może opierać się na interfejsach API specyficznych dla przeglądarki. Używanie globalnych obiektów, takich jak window, document, navigator czy location, a także niektórych właściwości HTMLElement, spowoduje błędy w czasie wykonywania po stronie serwera. Zamiast tego korzystaj z abstrakcji zgodnych z SSR, które udostępnia Angular. Na przykład, zamiast bezpośrednio odwoływać się do obiektu document, można użyć tokenu DOCUMENT w serwisie, takim jak SeoService. Dzięki temu kod będzie działał bezpiecznie zarówno na serwerze, jak i w przeglądarce.
@Injectable({ providedIn: 'root' })
export class SeoService {
private readonly _titleService = inject(Title);
private readonly _metaService = inject(Meta);
private readonly _document = inject(DOCUMENT);
…
}Kolejne ograniczenie, o którym warto pamiętać, pojawia się podczas wyboru bibliotek zewnętrznych. Zawsze upewnij się, że są one kompatybilne z SSR i nie polegają na mechanizmach przeglądarkowych w swojej wewnętrznej implementacji. W aplikacji demonstracyjnej strona „About” wyświetla mapę z lokalizacją sklepu przy użyciu biblioteki LeafletJS, która stanowi doskonały przykład narzędzia korzystającego z manipulacji DOM.
Jeśli potrzebujesz dostępu do API dostępnych wyłącznie w przeglądarce, upewnij się, że ich wykonywanie jest ograniczone do środowiska przeglądarkowego. Można to zrobić, opakowując kod wewnątrz lifecycle hooks takich jak afterNextRender lub afterEveryRender, ponieważ są one uruchamiane tylko w przeglądarce i pomijane po stronie serwera.
export class AboutPageComponent {
private readonly _seoService = inject(SeoService);
constructor() {
this._seoService.setSeoData(getAboutPageSeo());
afterNextRender(async () => {
await this._initializeMap();
});
}
private async _initializeMap(): Promise<void> {
const lat = 52.225996;
const lng = 20.949808;
const zoom = 16;
try {
const L = await import('leaflet');
const map = L.map('map').setView([lat, lng], zoom);
L.marker([lat, lng]).addTo(map);
L.tileLayer('https://{s}.tile.openstreetmap.org/{z}/{x}/{y}.png', {
attribution:
'© <a href="https://www.openstreetmap.org/copyright">OpenStreetMap</a> contributors',
}).addTo(map);
} catch (error) {
console.error('Failed to initialize map:', error);
}
}
}
Jeśli musisz wykonać tego typu sprawdzenie poza komponentem lub dyrektywą, gdzie lifecycle hooks nie są dostępne, możesz wstrzyknąć token PLATFORM_ID. Dzięki niemu możesz skorzystać z narzędzia isPlatformBrowser, aby uruchamiać kod tylko w przeglądarce (lub z isPlatformServer, jeśli chcesz, aby kod wykonywał się wyłącznie po stronie serwera).
export const initializeMap = async (containerId: string): Promise<void> => {
const platformId = inject(PLATFORM_ID);
if (!isPlatformBrowser(platformId)) return;
const lat = 52.225996;
const lng = 20.949808;
const zoom = 16;
try {
const L = await import('leaflet');
const map = L.map(containerId).setView([lat, lng], zoom);
L.marker([lat, lng]).addTo(map);
} catch (error) {
console.error('Failed to initialize map:', error);
}
};Zdecydowałem się użyć tego trybu renderowania dla strony głównej oraz strony wyszukiwania produktów. Ponieważ strony te wyświetlają wyniki wyszukiwania, które mogą często się zmieniać, logicznym rozwiązaniem było ich renderowanie po stronie serwera. Dzięki temu uzyskuję wszystkie korzyści SEO, utrzymując wysoką pozycję w wynikach wyszukiwania, a jednocześnie zapewniam, że klienci zawsze widzą najbardziej aktualne treści. To rozwiązanie typu win-win, korzystne zarówno dla doświadczenia użytkownika, jak i dla wyników biznesowych.
Prerendering (SSG)
W trybie prerenderingu dokument HTML jest generowany na etapie budowania aplikacji. Dzięki temu strony ładują się znacznie szybciej, ponieważ serwer może odpowiedzieć bezpośrednio statycznym plikiem, bez konieczności wykonywania dodatkowych operacji.
Kolejną dużą zaletą tego podejścia jest możliwość efektywnego cachowania. Statyczne pliki mogą być skutecznie przechowywane w pamięci podręcznej przez sieci dostarczania treści (CDN), przeglądarki oraz inne warstwy cache’u, co prowadzi do jeszcze szybszego ładowania stron przy kolejnych odwiedzinach. W rzeczywistości w pełni statyczna witryna może być wdrożona całkowicie za pośrednictwem CDN lub prostego serwera plików statycznych, co eliminuje konieczność utrzymywania niestandardowego środowiska serwerowego dla aplikacji.
Aby zobaczyć wynik tego procesu, zbuduj aplikację i następnie otwórz folder dist:
Podobnie jak SSR, prerendering zapewnia znaczący wzrost wydajności SEO, ponieważ wyszukiwarki otrzymują w pełni wyrenderowany dokument HTML. Obowiązuje tu jednak to samo ograniczenie: należy unikać bezpośredniego używania API specyficznych dla przeglądarki.
Dodatkowym ograniczeniem jest to, że wszystkie dane wymagane do renderowania muszą być dostępne w momencie budowania aplikacji. Oznacza to, że strony prerenderowane nie mogą zależeć od danych użytkownika ani od informacji, które zmieniają się przy każdym żądaniu. Z tego powodu prerendering najlepiej sprawdza się w przypadku stron, które są identyczne dla wszystkich użytkowników.
Ponieważ prerendering odbywa się na etapie budowania, może on zauważalnie wydłużyć czas tworzenia produkcyjnych wersji aplikacji. Generowanie dużej liczby dokumentów HTML nie tylko zwiększa czas kompilacji, ale również może znacząco zwiększyć rozmiar paczki wdrożeniowej. W rezultacie proces wdrażania może być wolniejszy oraz wymagać większej ilości miejsca lub przepustowości.
Dostosowywanie prerenderingu
Aby prerenderować strony ze sparametryzowaną ścieżką, można zdefiniować asynchroniczną funkcję getPrerenderParams. Funkcja ta zwraca tablicę obiektów, z których każdy stanowi mapę par klucz-wartość, gdzie klucze odpowiadają nazwom parametrów ścieżek, a wartości ich konkretnym danym.
Wewnątrz tej funkcji możesz użyć funkcji inject dostarczanej przez Angulara, aby uzyskać dostęp do zależności oraz wykonać wszelkie niezbędne operacje potrzebne do określenia, które strony powinny zostać prerenderowane. Typowym podejściem jest wykonywanie wywołań API w celu pobrania danych, które następnie posłużą do zbudowania tablicy wartości parametrów.
{
path: 'products/:id',
renderMode: RenderMode.Prerender,
getPrerenderParams: async () => {
const productService = inject(ProductService);
const products = await firstValueFrom(productService.searchProducts(), {
defaultValue: [],
});
return products.map((product) => ({ id: product.id }));
},
},
Używając właściwości fallback, możesz zdefiniować strategię obsługi żądań kierowanych do ścieżek, które nie zostały prerenderowane. Dostępne opcje to:
- Server – przełączenie na renderowanie po stronie serwera (SSR, domyślna opcja)
- Client – przełączenie na renderowanie po stronie klienta (CSR)
- None – żądanie nie zostanie obsłużone
Renderowanie po stronie klienta
Ten tryb przywraca domyślne zachowanie Angulara. Jest to najprostsze podejście, ponieważ możesz pisać kod tak, jakby zawsze miał być wykonywany w przeglądarce, i swobodnie korzystać z szerokiego wachlarza bibliotek klienckich.
Minusem jest jednak to, że tracisz wszystkie korzyści SSR, co negatywnie wpływa na wydajność oraz SEO.
Z drugiej strony, serwer nie musi wykonywać żadnych dodatkowych operacji poza serwowaniem statycznych zasobów JavaScript. Może to być zaletą w sytuacjach, gdy koszty utrzymania serwera są istotnym czynnikiem, szczególnie w przypadku stron, dla których SSR nie przynosi większej wartości, na przykład panelu administracyjnego.
Hydracja (Hydration)
Zgodnie z dokumentacją Angulara:
Hydracja to proces, który przywraca aplikację renderowaną po stronie serwera (SSR) do działania po stronie klienta. Obejmuje on między innymi ponowne wykorzystanie struktur DOM wygenerowanych przez serwer, utrzymanie stanu aplikacji, przeniesienie danych pobranych już wcześniej przez serwer oraz inne powiązane procesy.
Termin hydracja jest bardzo trafny. Pomocną analogią jest róża pustyni (resurrection plant). W swoim wysuszonym stanie, pod pustynnym słońcem, przypomina ona statyczny HTML dostarczony z serwera – kompletny pod względem struktury i wyglądu, lecz pozbawiony życia i interaktywności.
Dodanie wody przywraca ją do życia. W podobny sposób hydration w Angularze ożywia stronę, przekształcając statyczny, choć w pełni uformowany HTML w dynamiczną, interaktywną aplikację, jednocześnie ponownie wykorzystując całą pracę wykonaną podczas renderowania po stronie serwera.
Dopasowywanie istniejących elementów DOM w czasie działania aplikacji i ich ponowne wykorzystanie, gdy to możliwe, eliminuje potrzebę ich niszczenia i ponownego tworzenia. Prowadzi to do zwiększenia wydajności poprzez redukcję opóźnienia pierwszej interakcji (FID – First Input Delay) oraz przyspieszenie czasu załadowania głównego elementu strony (LCP – Largest Contentful Paint).
Dodatkowo, hydracja zapobiega migotaniu interfejsu i przesunięciom layoutu, co poprawia wynik Cumulative Layout Shift (CLS). Lepsze wyniki w tych metrykach nie tylko zwiększają komfort użytkowania, ale również pozytywnie wpływają na SEO.
Aby sprawdzić, czy hydracja jest włączona i działa poprawnie, otwórz Developer Tools. W konsoli powinien pojawić się komunikat potwierdzający, zawierający statystyki związane z hydracją, np.:
Angular hydrated 5 component(s) and 65 node(s), 0 component(s) were skipped.
5 defer block(s) were configured to use incremental hydration.
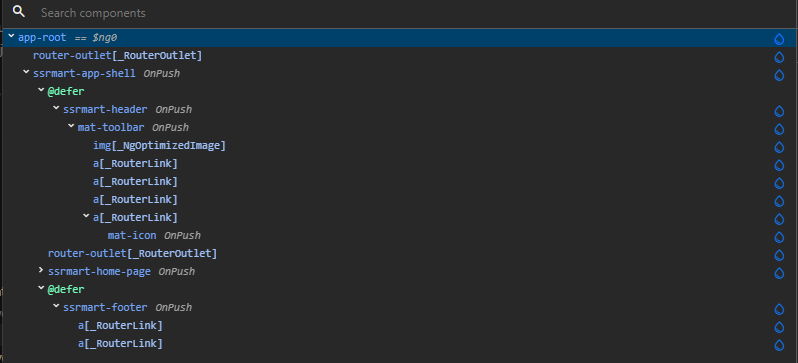
Możesz również skorzystać z rozszerzenia Angular DevTools dla przeglądarki. W drzewie komponentów szukaj ikon kropli wody, albo włącz warstwę hydration overlay, aby zobaczyć, które elementy strony zostały zhydrowane.
Odtwarzanie zdarzeń (Replaying events)
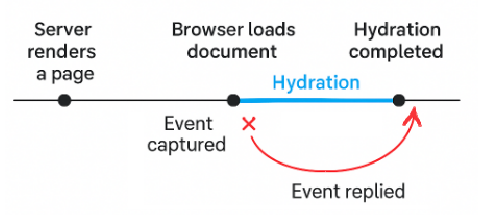
Kiedy strona zostanie wyrenderowana po stronie serwera, staje się widoczna dla użytkownika natychmiast po załadowaniu dokumentu HTML przez przeglądarkę. Na tym etapie strona może wyglądać na gotową, jednak aplikacja nie jest jeszcze interaktywna. Hydracja musi się zakończyć, zanim Angular będzie w stanie w pełni powiązać swoją logikę z elementami DOM.
Może to jednak prowadzić do problemu: co się stanie, jeśli użytkownik spróbuje kliknąć przycisk, wpisać coś w polu tekstowym lub w inny sposób wejść w interakcję ze stroną zanim hydracja się zakończy? Bez odpowiedniego rozwiązania takie wczesne interakcje zostałyby po prostu utracone. Tutaj z pomocą przychodzi funkcjonalność Event Replay.
Funkcja ta zapewnia, że interakcje użytkownika są zachowywane w czasie, gdy aplikacja nie jest jeszcze interaktywna. Działa ona w trzech krokach:
- Capture – wszystkie natywne zdarzenia przeglądarki (takie jak kliknięcia, naciśnięcia klawiszy czy przewijanie), które wystąpią przed zakończeniem hydracji zostają przechwycone.
- Store – przechwycone zdarzenia są tymczasowo zapisywane w pamięci, podczas gdy Angular nadal przeprowadza hydrację.
- Replay – po zakończeniu hydracji i pełnym uaktywnieniu aplikacji, Angular odtwarza zapisane zdarzenia, tak jakby miały miejsce przed chwilą.
Tą funkcję możemy uruchomić za pomocą withEventReplay():
bootstrapApplication(App, {
providers: [
provideClientHydration(withEventReplay())
]
});
Jeśli jednak korzystasz z inkrementalnej hydracji, funkcja odtwarzania zdarzeń jest domyślnie włączona.
Inkrementalna hydracja (Incremental hydration)
Inkrementalna hydracja to zaawansowana technika, która pozwala, aby poszczególne części aplikacji pozostały w stanie niezhydrowanym i były hydrowane stopniowo, na żądanie, zamiast wszystkiego naraz. Takie podejście zapewnia precyzyjną kontrolę nad procesem, zwiększa wydajność poprzez zmniejszenie początkowego rozmiaru bundle i jednocześnie oferuje doświadczenie użytkownika porównywalne z pełną hydracją.
Mechanizm ten wykorzystuje znaną składnię bloku @defer, który definiuje granicę dla inkrementalnej hydracji oraz trigger, który określa moment jego uruchomienia. Podczas renderowania po stronie serwera Angular ładuje zawartość bloku @defer i renderuje ją w miejscu elementu zastępczego (placeholdera). Po stronie klienta natomiast zależności te pozostają odroczone, a zawartość pozostaje niezhydrowana, dopóki wyzwalacz hydracji (hydrate trigger) nie zostanie aktywowany.
Hydracja ma miejsce tylko podczas początkowego ładowania strony, gdy treść renderowana jest po stronie serwera. W przypadku kolejnych załadowań stron renderowanych po stronie klienta (np. gdy użytkownik przechodzi do innej strony za pomocą routerLink), Angular powraca do standardowego zachowania bloku @defer.
Po zakończeniu procesu hydracji wszystkie zdarzenia przeglądarkowe (zwłaszcza te odpowiadające nasłuchiwanym przez komponenty zdarzeniom), które wystąpiły przed zakończeniem hydracji, są odtwarzane przy użyciu mechanizmu Event Replay Angulara.
Warto pamiętać, że defer używa idle jako domyślnego wyzwalacza, jeśli żaden inny nie został jawnie określony. Jeśli zdecydujesz się użyć innego wyzwalacza po stronie klienta, możesz również potrzebować zdefiniować blok @placeholder.
@Component({
selector: 'ssrmart-app-shell',
template: `
@defer (hydrate on hover) {
<ssrmart-header />
}
<main class="flex-1">
<router-outlet />
</main>
@defer (hydrate on interaction; on immediate) {
<ssrmart-footer />
} @placeholder {
<footer class="footer-placeholder"></footer>
}
`,
changeDetection: ChangeDetectionStrategy.OnPush,
imports: [HeaderComponent, FooterComponent, RouterOutlet],
host: {
class: 'flex flex-col min-h-screen',
},
})
export default class AppShellComponent {}
Na potrzeby tej demonstracji zdefiniowałem hydration trigger jako hover (choć w praktyce zazwyczaj użyłbym wyzwalacza interaction, tak jak w przypadku stopki). Jak widać, po najechaniu kursorem na nagłówek, Angular hydruje ten element i leniwe ładuje (lazy-loads) odpowiednie fragmenty kodu dla komponentów HeaderComponent, MatToolbar oraz MatIcon, podczas gdy stopka pozostaje w stanie niezhydrowanym.
Dostępne wyzwalacze to:
on idle – gdy przeglądarka osiągnie stan bezczynności (wykrywane za pomocą requestIdleCallback)
on viewport – gdy zawartość pojawi się w obszarze widoku (wykrywane przy użyciu Intersection Observer API)
on interaction – gdy użytkownik wchodzi w interakcję z elementem, np. poprzez kliknięcie lub naciśnięcie klawisza
on hover – gdy użytkownik najedzie kursorem na zawartość (mouseover) lub skupi na niej uwagę (focusin)
on immediate – natychmiast po zakończeniu renderowania całej pozostałej, nieodroczonej zawartości
on timer – po upływie określonego czasu
when condition – gdy określony warunek logiczny zostanie spełniony (zwróci wartość „truthy”)
Szczególnym przypadkiem jest wyzwalacz never, który instruuje Angulara, aby pozostawił blok w stanie niezhydrowanym na czas nieokreślony, traktując go jako statyczną zawartość. To rozwiązanie jest szczególnie przydatne w przypadku nieinteraktywnych lub dekoracyjnych sekcji, które nie odnoszą korzyści z aktywacji JavaScriptu. Dodatkowo, wyzwalacz never blokuje proces hydratyzacji dla wszystkich elementów potomnych, dzięki czemu żadne zagnieżdżone wyzwalacze nie zostaną uruchomione.
Warto również wspomnieć o zagnieżdżonych wyzwalaczach hydracji. System komponentów Angulara jest hierarchiczny, co oznacza, że aby dany komponent mógł zostać zhydrowany, wszystkie jego komponenty nadrzędne muszą wcześniej przejść ten proces. Jeśli więc wyzwalacz hydracji zostanie aktywowany w bloku zagnieżdżonym w strukturze niezhydrowanej, Angular rozpoczyna proces hydracji od najwyższego komponentu nadrzędnego, a następnie kontynuuje w dół hierarchii, aż do wywołanego bloku.
Aby zobrazować ten proces, owiniemy główny router-outlet w blok @defer z wyzwalaczem interaction. Następnie, dla kart produktów w sekcji Bestsellers na stronie głównej, zastosujemy blok @defer z wyzwalaczem hover.
Wynik wygląda następująco:
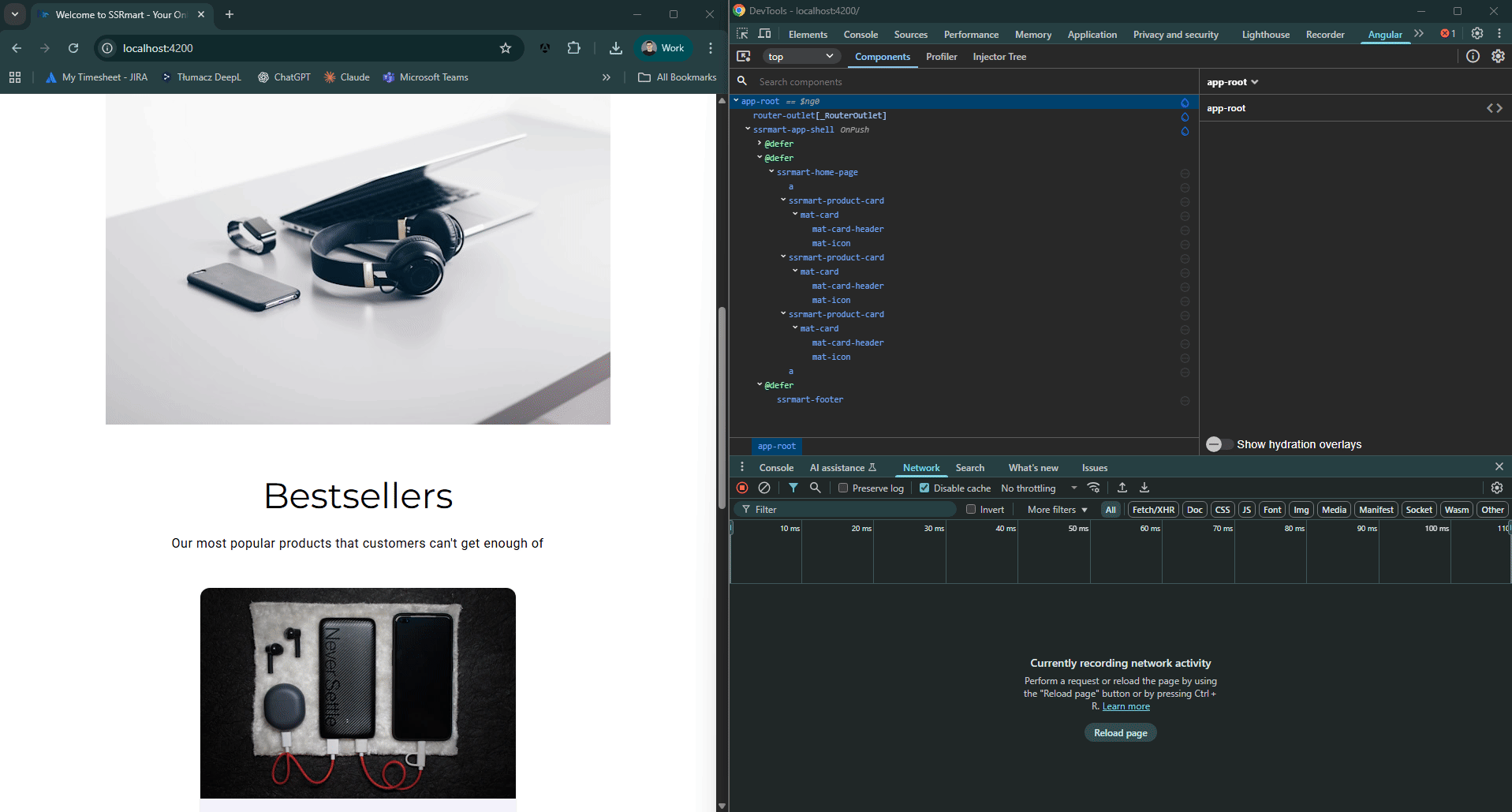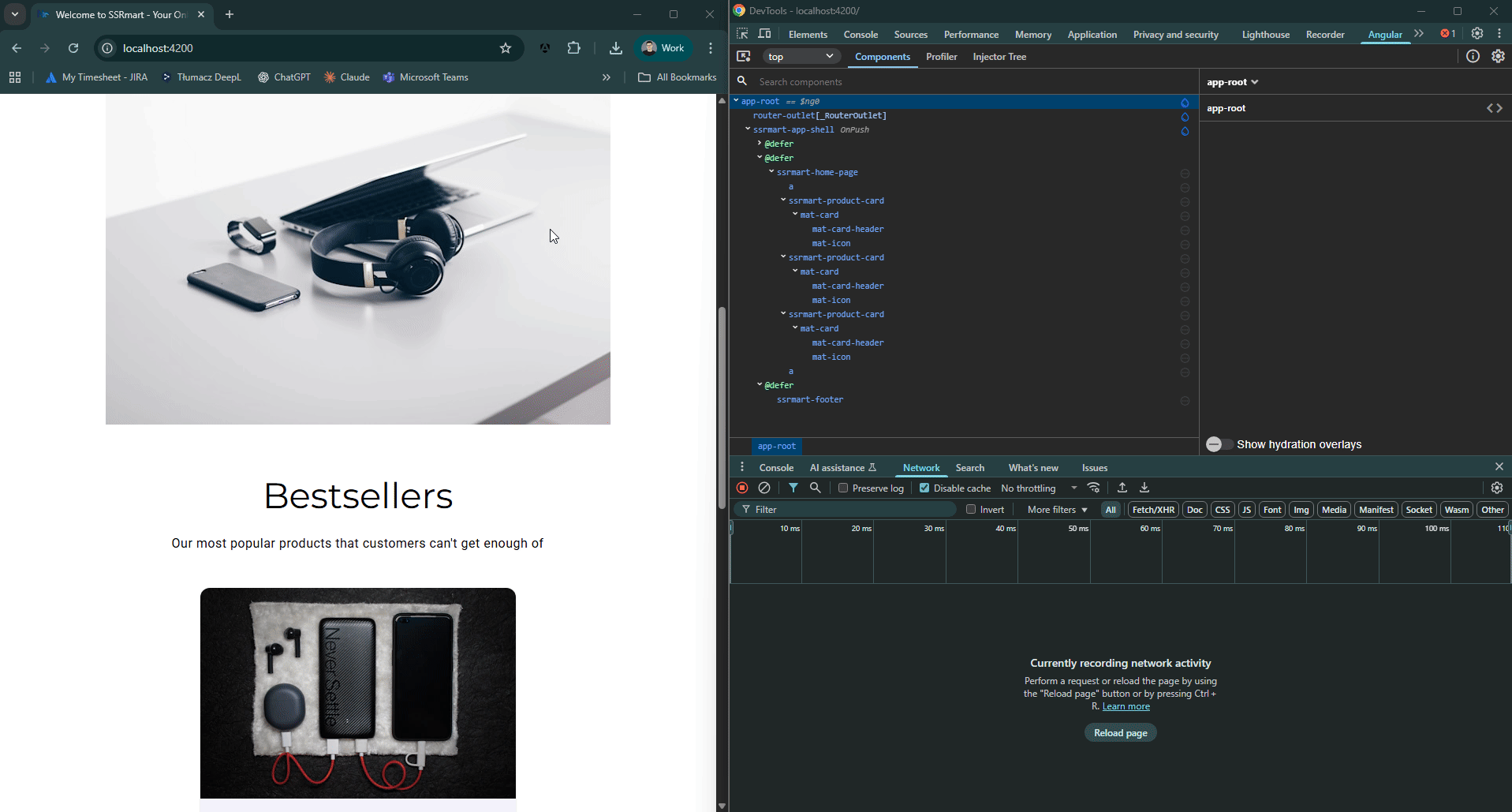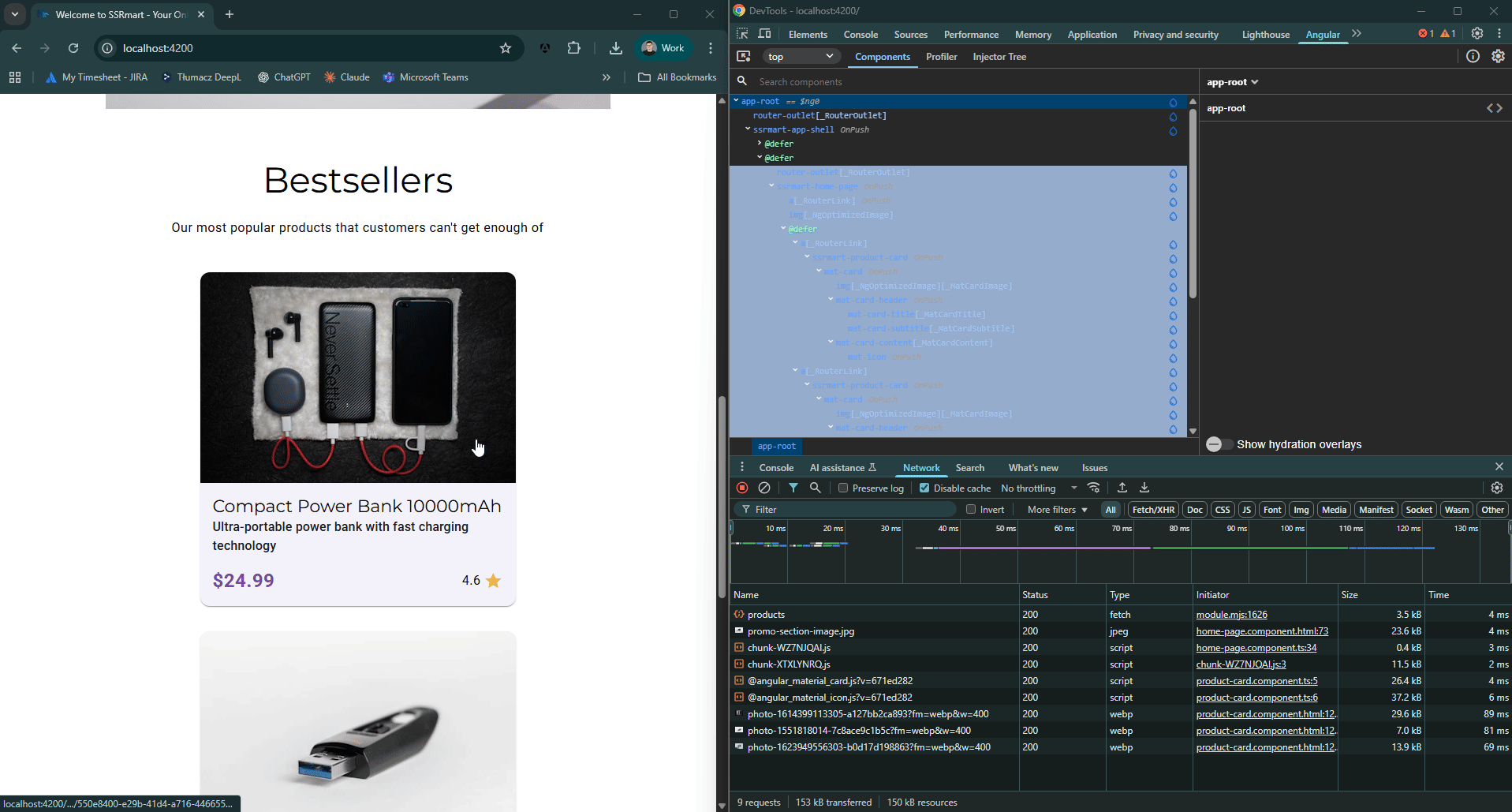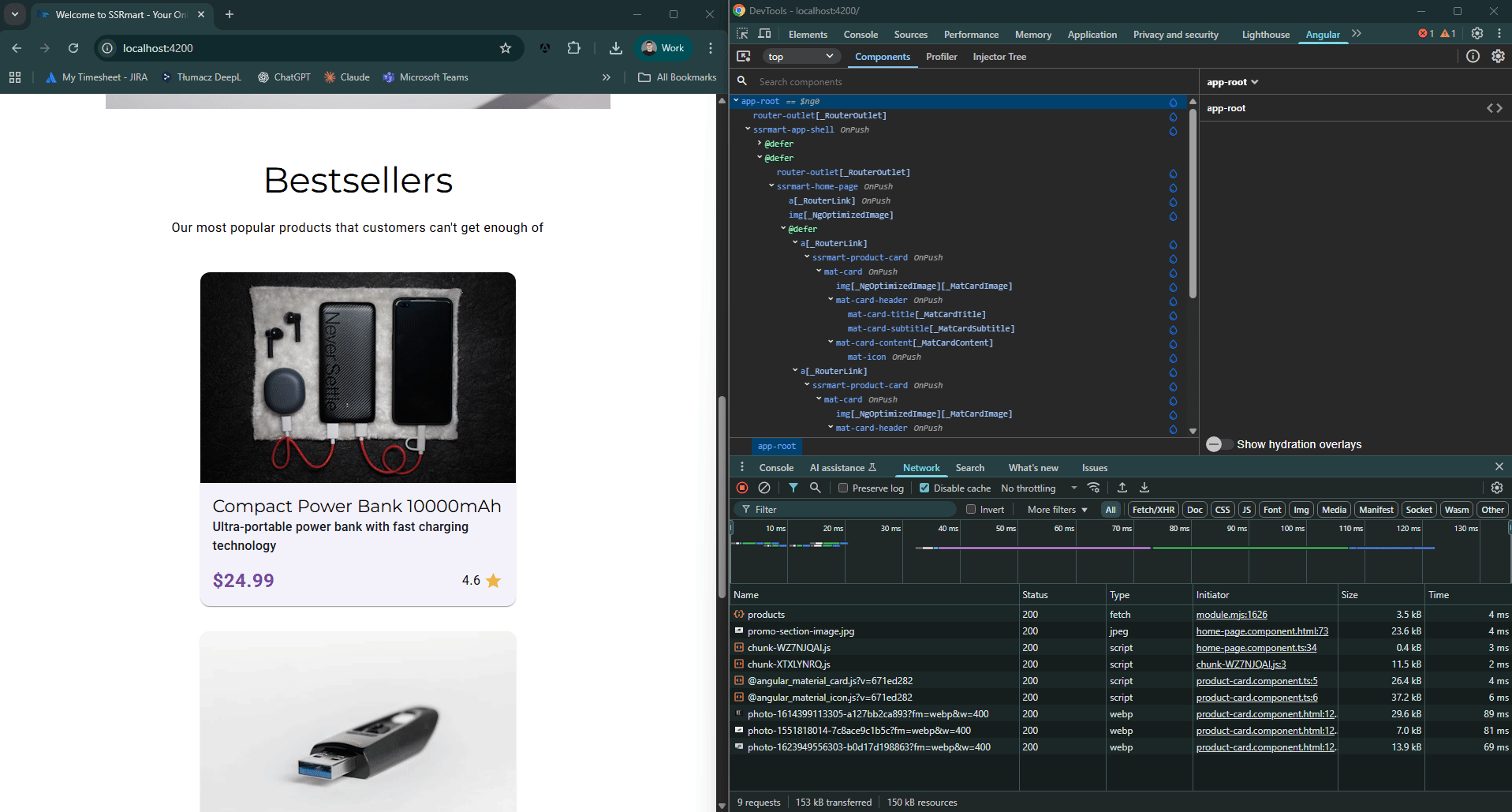
Ograniczenia
Kiedy Angular wykonuje proces hydracji, ponownie wykorzystuje HTML wyrenderowany po stronie serwera zamiast renderować wszystko od zera w przeglądarce. Aby ten proces zakończył się powodzeniem, struktura DOM po stronie serwera i po stronie przeglądarki musi być identyczna.
Unikaj bezpośredniej manipulacji DOM
Proces hydratacji zakłada, że Angular ma pełną kontrolę nad strukturą DOM. Jeśli manipulujesz DOM bezpośrednio (na przykład poprzez wyszukiwanie konkretnych elementów, ręczne dodawanie, przenoszenie lub usuwanie elementów), Angular nie ma świadomości tych zmian.
Ponieważ Angular nie jest świadomy takich modyfikacji, nie jest w stanie rozwiązać różnic pomiędzy DOMem wyrenderowanym po stronie serwera a DOMem po stronie przeglądarki podczas procesu hydracji. W efekcie może to prowadzić do błędów lub niepowodzenia całego procesu hydracji aplikacji.
Nie opieraj się na logice renderowania zależnej od środowiska
Środowisko serwera różni się zasadniczo od środowiska przeglądarki. Właściwości i API dostępne w przeglądarce (takie jak window, localStorage, charakterystyka urządzenia, preferencje użytkownika czy inne stany specyficzne dla przeglądarki), są niedostępne po stronie serwera lub zwracają inne wartości.
Jeśli Twój komponent renderuje różną zawartość w zależności od tych zmiennych środowiskowych, prowadzi to do niespójności pomiędzy tym, co zostało wyrenderowane po stronie serwera, a tym, czego oczekuje przeglądarka w trakcie procesu hydratacji.
Zamiast tego, należy utrzymywać spójną strukturę DOM i odraczać logikę zależną od środowiska, na przykład poprzez zastosowanie CSS lub wykonywanie takiej logiki po zakończeniu hydracji.
Zadbaj o poprawną strukturę HTML
Przeglądarki są dość pobłażliwe wobec niepoprawnego kodu HTML. Jeśli Twoje szablony generują niepoprawny kod, przeglądarka może go „naprawić” w locie, na przykład poprzez zamykanie niezamkniętych znaczników, zmianę sposobu zagnieżdżenia elementów, lub usuwanie nieprawidłowych węzłów. Choć taka automatyczna korekta może wydawać się wygodna, powoduje poważny problem podczas procesu hydracji: naprawiony DOM po stronie przeglądarki nie jest już identyczny z DOMem wyrenderowanym po stronie serwera. Taka niespójność powoduje, że proces hydracji zawodzi.
Dlatego należy zawsze pisać poprawny, dobrze sformatowany kod HTML w szablonach Angulara oraz rozważyć użycie narzędzi walidacyjnych lub ścisłych reguł szablonów (Angular strict template checks), aby wykrywać błędy na wczesnym etapie.
Zachowanie białych znaków
Proces hydratacji nie ogranicza się jedynie do porównywania elementów. Sprawdza również białe znaki oraz komentarze wygenerowane podczas renderowania po stronie serwera. Jeśli znaki te zostaną zachowane po stronie serwera, ale potraktowane inaczej po stronie przeglądarki, Angular wykryje różnicę, co również może prowadzić do błędu hydracji.
Aby uniknąć tego problemu, Angular zaleca pozostawienie opcji preserveWhitespaces w domyślnej wartości false. Zapewnia to spójny wynik renderowania między serwerem a klientem.
Niestandardowy lub Noop Zone.js
Proces hydracji opiera się na sygnale pochodzącym z biblioteki Zone.js, który informuje Angulara, że aplikacja osiągnęła stan stabilny. W tym momencie Angular może rozpocząć proces serializacji po stronie serwera, lub wykonać czyszczenie po hydracji po stronie klienta, usuwając wszelkie nieprzypisane węzły DOM.
Używanie niestandardowej implementacji Zone.js lub tzw. „noop” Zone.js (czyli wersji pozbawionej aktywnego śledzenia stref) może wpłynąć na moment wysyłania sygnału „stable”. Taka konfiguracja nie jest jeszcze w pełni wspierana, dlatego należy jej unikać w środowiskach, w których kluczowa jest poprawna obsługa hydracji.
Pomijanie procesu hydratacji
Z powodów wymienionych powyżej proces hydracji może nie działać poprawnie z niektórymi komponentami. Zalecanym podejściem jest zrefaktoryzowanie tych komponentów, aby uczynić je kompatybilnymi z procesem hydracji. Jeśli jednak refaktoryzacja okaże się zbyt złożona lub czasochłonna, istnieje rozwiązanie awaryjne. Możliwe jest użycie atrybutu ngSkipHydration, który instruuje Angulara, aby pominął proces hydracji dla danego komponentu.
<hydration-incompatible-component ngSkipHydration />
or
@Component({
…,
host: { ngSkipHydration: ‘true’ }
})
export class HydrationIncompatibleComponent {}
Gdy atrybut ten zostanie zastosowany do węzła hosta komponentu, instruuje on Angulara, aby pominął ten proces dla tego komponentu oraz wszystkich jego potomków. W rezultacie, elementy te zostaną zniszczone i ponownie wyrenderowane po stronie klienta.
Interakcje z żądaniami i odpowiedziami
Żądania (requests) i odpowiedzi (responses) pełnią rolę mostów między danymi specyficznymi dla serwera a komponentami i serwisami Angulara, stanowiąc fundament renderowania po stronie serwera z uwzględnieniem kontekstu. Aby umożliwić tę komunikację, Angular udostępnia specjalne tokeny wstrzykiwania zależności (dependency injection tokens).
Należy jednak pamiętać, że poniższe tokeny przyjmują wartość null w następujących sytuacjach:
- podczas procesu budowania aplikacji
- podczas renderowania aplikacji po stronie klienta
- przy użyciu statycznego generowania stron
- w trakcie ekstrakcji tras w developmencie
Request
Token REQUEST zapewnia dostęp do aktualnego obiektu Request pochodzącego z Web API. Obiekt ten udostępnia szczegółowe informacje o przychodzącym żądaniu, które mogą być niezwykle przydatne w wielu kontekstach, między innymi:
- Profilowanie klienta – umożliwia określenie typu urządzenia, języka użytkownika oraz ustawień lokalizacyjnych
- Kontekst bezpieczeństwa – pozwala sprawdzić, czy połączenie jest szyfrowane, z jakiej domeny pochodzi odwołanie, a także uzyskać dostęp do nagłówków uwierzytelniających
- Optymalizacja wydajności i SEO – umożliwia wdrażanie dynamicznych strategii renderowania oraz dostosowywanie zasad buforowania
export const getCookie = (name: string): string => {
const document = inject(DOCUMENT);
const request = inject(REQUEST);
const platformId = inject(PLATFORM_ID);
const cookies = isPlatformServer(platformId)
? request?.headers.get('cookie') ?? ''
: document.cookie;
return cookies.match('(^|;)\\s*' + name + '\\s*=\\s*([^;]+)')?.pop() ?? '';
};
Kontekst żądania
Podczas gdy token REQUEST dostarcza surowych informacji HTTP, token REQUEST_CONTEXT reprezentuje przetworzony, konkretny dla aplikacji kontekst. Pełni on rolę repozytorium rozszerzonych danych o żądaniu, łącząc surowe dane żądania, logikę biznesową, profile użytkowników oraz aktualny stan aplikacji. Taki kontekst może zostać przekazany jako drugi parametr funkcji handle w pliku server.ts, co pozwala na dostęp do kontekstowych danych w trakcie renderowania po stronie serwera.
app.use('/**', (req, res, next) => {
const enableCustomerChat =
!isBotUserAgent(req.headers['user-agent']) &&
isFeatureFlagEnabled('customer_chat');
angularApp
.handle(req, {
enableCustomerChat,
})
.then((response) =>
response ? writeResponseToNodeResponse(response, res) : next()
)
.catch(next);
});Response
Token RESPONSE_INIT zapewnia dostęp do opcji inicjalizacji odpowiedzi. Dzięki niemu można dynamicznie ustawiać nagłówki oraz kod statusu odpowiedzi. Token ten należy wykorzystywać wszędzie tam, gdzie nagłówki lub kody statusu muszą być określane w czasie wykonywania aplikacji, na przykład w zależności od logiki biznesowej, kontekstu żądania lub wyniku przetwarzania danych po stronie serwera.
export default class ProductNotFoundPageComponent {
private readonly _responseInit = inject(RESPONSE_INIT);
constructor() {
if (!this._responseInit) return;
this._responseInit.status = 404;
this._responseInit.headers = { 'Cache-Control': 'no-cache' };
}
}
Jeśli jednak z góry wiesz, jaki kod statusu lub jakie nagłówki powinny zostać uwzględnione w odpowiedzi, możesz je zdefiniować bezpośrednio w ścieżkach serwera.
{
path: 'products/not-found',
renderMode: RenderMode.Server,
headers: { 'Cache-Control': 'no-cache' },
status: 404,
},
Buforowanie HTTP (Caching)
Angular buforuje żądania wysyłane podczas renderowania po stronie serwera i ponownie wykorzystuje je w trakcie początkowego renderowania po stronie klienta. Odpowiedzi na te żądania są serializowane i osadzane w inicjalnej odpowiedzi serwera, dzięki czemu Angular może korzystać z tej pamięci podręcznej do momentu, aż aplikacja osiągnie stan stabilny.
Poniżej znajduje się przykład zbuforowanego żądania wyszukiwania dla produktów bestsellerowych wyświetlanych na stronie głównej:
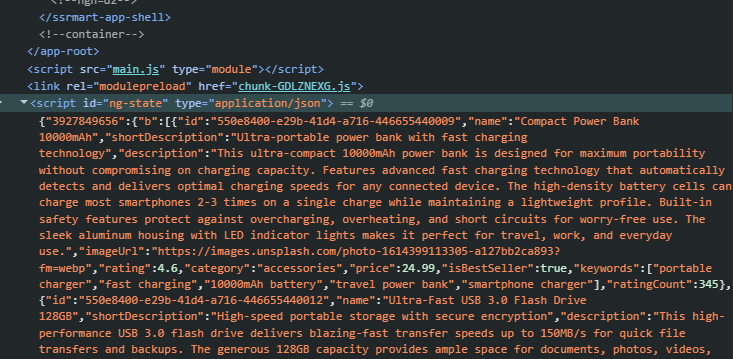
Domyślnie buforowane są jedynie żądania typu GET i HEAD, które nie zawierają nagłówków Authorization ani Proxy-Authorization. To zachowanie można dostosować za pomocą funkcji withHttpTransferCacheOptions używanej w provideClientHydration. Dzięki niej możesz:
- Uwzględnić żądania POST – szczególnie przydatne w przypadku zapytań wyszukiwania z wieloma parametrami
- Uwzględnić żądania z nagłówkami autoryzacji – pozwala to na korzystanie z buforowania także dla danych zabezpieczonych
- Zdefiniować własną funkcję filtrującą – określającą, które żądania powinny być buforowane (w mojej implementacji opiera się to na HttpContextToken)
- Wskazać nagłówki odpowiedzi, które mają być uwzględnione w JSONie zserializowanej odpowiedzi
provideClientHydration(
withHttpTransferCacheOptions({
includePostRequests: true,
includeRequestsWithAuthHeaders: true,
filter: (request) => !request.context.get(SKIP_HYDRATION_CACHE),
includeHeaders: ['Content-Type'],
})
),
Można to wyłączyć, używając:
provideClientHydration(
withNoHttpTransferCache()
),Transfer State
Aby przekazywać zbuforowane odpowiedzi, Angular korzysta z mechanizmu Transfer State. Jest to magazyn danych typu klucz-wartość, który jest przekazywany z aplikacji renderowanej po stronie serwera do aplikacji uruchamianej po stronie klienta.
Transfer State jest dostępny jako token, dzięki czemu można go łatwo wykorzystać do przekazywania danych w szczególnych przypadkach. Wartości w tym magazynie są serializowane i deserializowane za pomocą metod JSON.stringify oraz JSON.parse. Oznacza to, że tylko typy prymitywne oraz obiekty niebędące instancjami klas zostaną przekazane w sposób bezstratny.
const specialHeaderStateKey = makeStateKey<string>('special-header');
const trasnferSpecialHeader = (): void => {
const transferState = inject(TransferState);
const request = inject(REQUEST);
const platformId = inject(PLATFORM_ID);
if (isPlatformServer(platformId)) {
transferState.set(
specialHeaderStateKey,
request?.headers.get('x-special-header') ?? null
);
}
};
const readSpecialHeader = (removeFromTransferState = false): string | null => {
const transferState = inject(TransferState);
const value = transferState.get(specialHeaderStateKey, null);
if (removeFromTransferState) {
transferState.remove(specialHeaderStateKey);
}
return value;
};

Analog.js
Wspominałem już o Analog.js – to naprawdę interesujące rozwiązanie w ekosystemie Angulara. Jest to pełnostosowy meta-framework, który oferuje nowoczesny DevEx dzięki takim funkcjom jak:
- Routing oparty na strukturze plików – eliminuje potrzebę ręcznej konfiguracji ścieżek. Wystarczy utworzyć pliki w katalogu src/app/pages, a Analog automatycznie generuje ścieżki na podstawie struktury folderów.
- API routes – pozwalają definiować funkcje serverless bezpośrednio w projekcie Angulara. Pliki umieszczone w katalogu src/server/routes są automatycznie udostępniane jako endpointy API. Taka współlokalizacja kodu frontendowego i backendowego upraszcza rozwój i wdrażanie aplikacji full-stack.
- Hybrydowy rendering – Analog ma wbudowane wsparcie dla renderowania po stronie serwera, a jednocześnie daje pełną kontrolę nad tym, jak renderowana jest każda strona. Możesz wybrać między SSR, SSG lub CSR dla poszczególnych tras.
- System budowania oparty na Vite – zapewnia szybki start serwera deweloperskiego, hot module replacement (HMR) oraz wydajne kompilacje produkcyjne.
Analog.js jest szczególnie dobrze dopasowany do aplikacji bogatych w treść, stron marketingowych, platform e-commerce oraz wszelkich projektów, w których SEO i szybkość początkowego ładowania strony są kluczowe. Framework ten zapewnia również bardziej płynne i spójne środowisko pracy full-stack, upraszczając proces tworzenia i wdrażania aplikacji.
Co istotne, Analog.js zachowuje pełną kompatybilność z ekosystemem Angulara, co oznacza, że możesz w dalszym ciągu korzystać z istniejących bibliotek, komponentów oraz narzędzi Angularowych, jednocześnie czerpiąc korzyści z rozszerzonych możliwości Analog.js.
Zachęcam do zapoznania się z naszym artykułem o Analog.js.
Wnioski
SSR w Angularze przeszedł długą drogę – od skomplikowanej, eksperymentalnej funkcji do rozwiązania, które można z powodzeniem wdrożyć w rzeczywistych projektach, nie tracąc przy tym nerwów. Korzyści wydajnościowe są jak najbardziej realne: szybsze ładowanie początkowe stron, lepsze pozycje w wynikach wyszukiwania (SEO) oraz bardziej zadowoleni użytkownicy, którzy nie muszą patrzeć na nieskończenie długo ładujące się spinnery.
Najważniejsze jednak, aby pamiętać, że SSR nie jest uniwersalnym rozwiązaniem dla każdej aplikacji Angularowej. Jeśli tworzysz panel administracyjny lub aplikację za uwierzytelnianiem, prawdopodobnie nie potrzebujesz SSR. Natomiast jeśli SEO ma znaczenie, serwujesz treści publicznie lub wydajność jest kluczowa dla Twojego biznesu, SSR może przynieść realne i wymierne korzyści. Szczególnie wartościowe jest podejście hybrydowe. Używaj SSR tam, gdzie przynosi korzyści, a renderowania po stronie klienta tam, gdzie jest to wystarczające.
SSR stale się rozwija dzięki ulepszeniom w edge computingu, lepszym strategiom cache’owania oraz ciągłemu skupieniu zespołu Angulara na poprawie doświadczenia deweloperskiego. Jeśli zastanawiałeś się nad wdrożeniem SSR, to teraz jest doskonały moment, żeby spróbować.