Wykrywanie zmian zawsze było gorącym tematem i nic dziwnego – to jedna z podstawowych koncepcji każdego frameworka. Niezależnie od tego, jak został zaprojektowany i zaimplementowany, detekcja zmian pozostaje jednym z najważniejszych zadań i jednocześnie jednym z głównych powodów, dla których programiści decydują się na pracę z frameworkami.
W Angularze temat ten budzi szczególne kontrowersje, głównie ze względu na „magiczną” naturę mechanizmów wykrywania zmian wspieranych przez Zone.js. W ostatnim czasie obszar ten przeszedł istotne usprawnienia, zwłaszcza za sprawą wprowadzenia sygnałów i możliwością rezygnacji z Zone.js. Spójrzmy więc, jakie ulepszenia zostały wprowadzone.
(Niekoniecznie) krótkie podsumowanie
Przed zagłębieniem się we wprowadzone zmiany, istotne jest, aby mieć przynajmniej podstawową wiedzę na temat mechanizmu wykrywania zmian, który działa w Angularze od lat. Ta podstawa pomoże nam lepiej zrozumieć nowe koncepcje, ponieważ opierają się one na istniejących, zamiast wprowadzać coś zupełnie nowego lub niezależnego (ewolucja, a nie rewolucja). Jeśli czujesz się komfortowo z tematem wykrywania zmian przed wprowadzeniem sygnałów i wykorzystaniem podejścia Zoneless, możesz rozważyć pominięcie tego rozdziału.
Omawiając wykrywanie zmian, uważam za pomocne podzielenie go na dwa aspekty wykonania: “kiedy” i “jak”. Poznanie obu elementów jest niezbędne do zrozumienia ogólnego procesu wykrywania zmian w Angularze.
Kiedy?
Jak można się spodziewać, element “kiedy” jest związany z planowaniem (scheduling) wykrywania zmian. Odpowiada na pytanie kiedy detekcja zmian jest wykonywana i jakie czynniki do tego prowadzą.
Pomijając możliwość ręcznego wyzwalania wykrywania zmian, to przede wszystkim zadanie frameworka, by robić to za nas. Jest to rola tzw. schedulera i od początków Angulara jego działanie opierało się na współpracy z biblioteką Zone.js. Ta biblioteka śledzi różne operacje poprzez modyfikowanie API przeglądarki i przechwytywanie wykonywania zadań.
Upraszczając nieco, można powiedzieć, że Zone Angulara (NgZone) weryfikuje, czy kolejka mikrozadań jest pusta po zakończeniu każdej przechwyconej operacji. Jeśli tak, emituje specjalne zdarzenie, które jest następnie wykorzystywane przez mechanizm planowania (scheduler), co ostatecznie skutkuje uruchomieniem wykrywania zmian. Nie będziemy tutaj wnikać w więcej szczegółów. Jeśli jednak nie jesteś zaznajomiony z tym mechanizmem, gorąco polecam lekturę tego artykułu (lub nawet wszystkich powiązanych artykułów artykuły, jeśli jesteś naprawdę zainteresowany).
Najważniejszym wnioskiem jest zrozumienie, że Zone.js dostarcza Angularowi wskazówek na temat zakończonych operacji, co skłania framework do reakcji poprzez uruchomienie wykrywania zmian. Co ważne, ten duet w tym momencie nie wie, czy w ogóle dane wykorzystane w szablonie (template) faktycznie uległy zmianie, co oznacza, że odświeżenie może być konieczne lub nie.
Jak?
Część „jak” koncentruje się na mechanice właściwego wykonania procesu, w tym na przechodzeniu przez drzewo komponentów i wykrywaniu zmian. Po zaplanowaniu pojedynczego przebiegu wykrywania zmian ważne jest, aby zrozumieć, co to oznacza dla naszej aplikacji, w jaki sposób zostanie on przeprowadzony i jakie będą jego wyniki.
Poniżej znajduje się zwięzłe podsumowanie podstaw wykrywania zmian, które będą nam potrzebne do dalszych dyskusji. Możesz także rozważyć przeczytanie tego podsumowania, które krótko wyjaśnia temat.
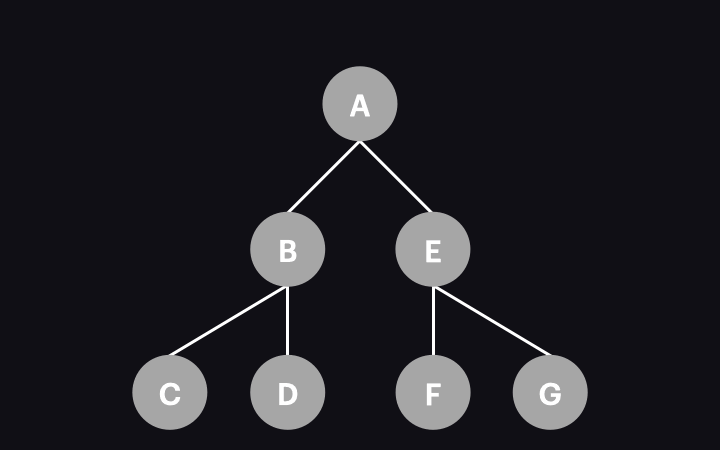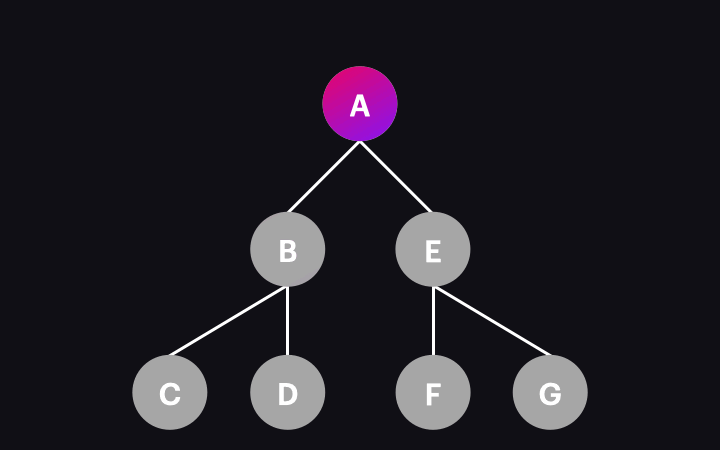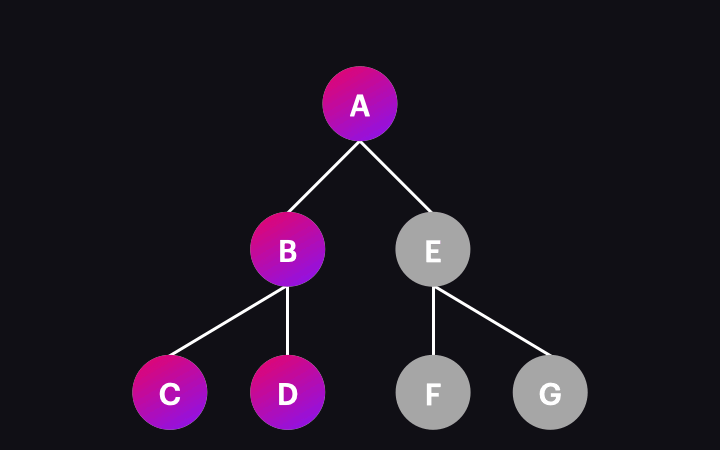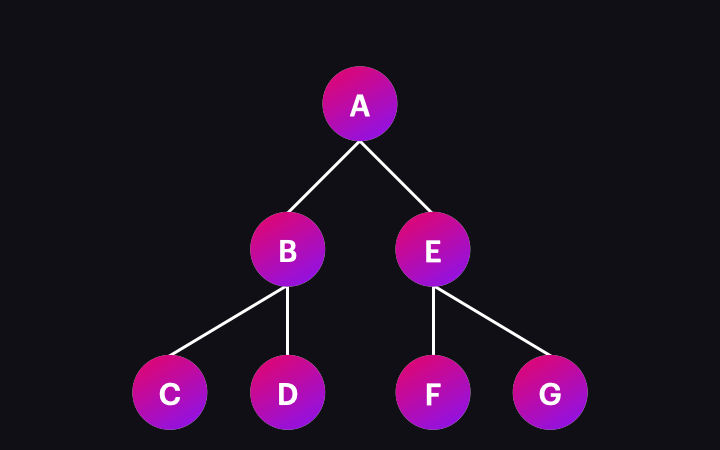
Struktura komponentów Angulara tworzy drzewo. W konfiguracji domyślnej poniższe zasady opisują sposób realizacji procesu na wysokim poziomie abstrakcji:
- Proces rozpoczyna się od komponentów będących w korzeniu drzewa (root components).
- Całe drzewo komponentów jest sprawdzane pod kątem zmian, co oznacza, że odwiedzany jest każdy węzeł.
- Kierunek przechodzenia jest z góry na dół.
- Dokładna kolejność odwiedzania węzłów jest zgodna z algorytmem przeszukiwania w głąb (DFS).
Poniższa animacja ilustruje ten proces:
Co się więc stanie, gdy pojedynczy węzeł zostanie odwiedzony i poddany detekcji zmian? Obejmuje to kilka operacji, w tym wykonywanie metod związanych z cyklem życia komponentu (lifecycle hooks), aktualizacja powiązań danych używanych w widoku, i odświeżenie widoku, jeśli to konieczne. Nie będziemy tutaj zagłębiać się w te szczegóły, ponieważ jest to zdecydowanie szerszy temat. Dla potrzeb tego artykułu wystarczy pamiętać, że jeśli rzeczywiście wystąpiła jakakolwiek zmiana danych, widok komponentu zostanie zaktualizowany w tym procesie i odzwierciedli tę zmianę.
Ważne jest również, aby uporać się z powszechnym mitem: komponenty Angular nie są „rerenderowane” podczas wykrywania zmian. Takie stwierdzenie sugeruje, że zostaje zastąpiona cała struktura DOM komponentu, co nie jest prawdą. Angular jest na tyle inteligentny, że potrafi aktualizować tylko te węzły DOM (lub nawet poszczególne atrybuty), które faktycznie wymagają zmiany.
Strategie wykrywania zmian – OnPush
W Angularze istnieją dwie strategie wykrywania zmian: Default i OnPush. Zasady opisane w rozdziale „Jak?” w zasadzie opisują strategię domyślną (Default). Czym więc różni się strategia OnPush?
Podstawowe zasady poruszania się po drzewie komponentów pozostają takie same, jednak OnPush pozwala nam „odciąć” lub pominąć niektóre gałęzie podczas wykrywania zmian. Prowadzi to do mniejszej liczby wykonywanych operacji, co skutkuje lepszą wydajnością.
Gdy komponent korzysta z OnPush, komponent ten (i jego dzieci) nie zawsze będą sprawdzane podczas wykrywania zmian. Zamiast tego będą sprawdzane tylko wtedy, gdy zostaną oznaczone jako „zmienione” (dirty). Cała gałąź jest pomijana, jeśli komponent nie jest oznaczony w ten sposób.
W aplikacji można mieszać komponenty Default i OnPush. Na przykład, jeśli komponent-rodzic używa OnPush, a dziecko Default, dziecko będzie nadal podlegało detekcji zmian zmian, tak długo jak mechanizm przechodzenia po drzewie będzie mógł dotrzeć do dziecka (co oznacza, że rodzic był dirty i nie został “odcięty” w danym przebiegu).
W tym miejscu możemy również powrócić do zasady, mówiącej że „całe drzewo komponentów jest sprawdzane pod kątem zmian, co oznacza, że odwiedzany jest każdy węzeł.”. Nie jest to już prawdą, jeśli używamy komponentów OnPush, co stanowi nasz wyjątek.
Poniżej możesz zobaczyć ilustrację procesu:

Oznaczanie jako dirty
W poprzedniej sekcji wspomnieliśmy, że strategia OnPush opiera się na znakowaniu komponentów jako dirty w procesie wykrywania zmian. Powstaje naturalne pytanie: co może oznaczyć węzeł jako dirty? Istnieje zamknięty zestaw operacji, które wprowadzają komponent w ten stan:
- Wartość inputa komponentu ulega zmianie (w sposób niemutowalny).
- Występuje zdarzenie powiązane z szablonem (w tym emitowanie danych z outputa i zdarzenia z host listenera).
- Pojawia się nowa wartość na wejściu
AsyncPipe. - Bezpośrednie wywołanie
ChangeDetectorRef.markForCheck(). - Zmiana stanu bloku
@defer.
Kolejną ważną kwestią jest to, że operacje te propagują się wyżej przez hierarchię komponentów. Jest to zadanie funkcji markViewDirty. Oznacza to, że nie tylko komponent, z którego pochodzi zmiana, jest oznaczony jako dirty (w powyższym przykładzie F), ale wszyscy jego przodkowie aż do korzenia są również oznaczeni (w naszym przypadku E i A). Dzięki temu zagnieżdżony komponent (F) może być zawsze odwiedzony przez mechanizm przechodzenia po drzewie i nie zostanie “odcięty” na żadnym rodzicu korzystającym z OnPush i nie będący dirty (jak E).
W przeciwnym razie, gdyby hipotetycznie tylko F został oznaczony jako dirty, przyszłe wykrywanie zmian rozpoczynające się od A zatrzymałoby się w E (ponieważ jest to OnPush i nie byłby dirty), nigdy nie osiągając F. To pokazuje, dlaczego oznaczenie wszystkich komponentów-przodków jest istotne.
Jedyny wyjątek od reguły propagowania ma miejsce, gdy komponent jest oznaczony jako dirty z powodu zmiany wartości inputa przekazywanego przez widok komponentu rodzica. W tym przypadku, skoro wartość jest aktualizowana, komponent-rodzic jest już właśnie w trakcie wykrywania zmian, więc nie ma potrzeby ponownego oznaczania go jako dirty. Zamiast tego oznaczany jest tylko komponent-dziecko otrzymujący wartość w inpucie, co umożliwia wykrycie w nim zmian po zakończeniu procesu w rodzicu.
Optymalizacja „jak” – sygnały
Teraz, gdy już odświeżyliśmy naszą wiedzę na temat dotychczasowych reguł rządzących detekcją zmian w Angularze, możemy zbadać, w jaki sposób można ulepszyć ten proces.
W ostatnim czasie to sygnały były siłą napędową wielu najbardziej ekscytujących ulepszeń frameworka i wykrywanie zmian nie jest tu wyjątkiem. Jeśli chodzi o optymalizację aspektu „jak”, sygnały oferują znaczną poprawę w stosunku do standardowego mechanizmu. Przyjrzyjmy się bliżej, jak działają te innowacje i co programiści muszą zrobić po swojej stronie, by z nich skorzystać.
Artykuł zakłada, że posiadasz już podstawową wiedzę na temat sygnałów, grafu ich zależności i powiązanych pojęć. Jeśli nie, gorąco polecam najpierw zapoznać się z obszernym artykułem Maxa Koretskyi’ego: Sygnały w Angular – szczegółowe informacje dla zapracowanych programistów.
Pierwszą kluczową koncepcją, którą należy zrozumieć, jest to, że z perspektywy grafu zależności sygnałów, widok komponentu działa jak konsument reaktywny (reactive consumer), co oznacza, że reaguje na odczyty sygnałów w widoku. Możemy to zwizualizować w następujący sposób:

Gdy sygnał odczytany w widoku przyjmie nową wartość, oznacza to, że reactive consumer jest oznaczany jako dirty. Ważne jest, aby podkreślić to rozróżnienie – to reactive consumer dołączony do widoku komponentu jest oznaczany jako dirty, a nie sam widok komponentu (tj. nie węzeł w drzewie komponentów). W przeciwnym razie byłby to taki sam proces, jak zwykła strategia OnPush. Dzięki temu rozróżnieniu otrzymamy inny wynik, o czym powiemy się za chwilę.
Jednak co tak właściwie oznaczenie reaktywnego konsumenta jako dirty oznacza dla naszej aplikacji? Cóż, to zależy od wersji Angulara, której używamy. Przed wersją 17 oznaczenie reaktywnego konsumenta jako dirty oznaczałoby również widok komponentu jako dirty, co skutkowało zachowaniem podobnym do AsyncPipe.
Najlepsze, co możemy osiągnąć w tym przypadku, to użycie go z OnPush dla wszystkich komponentów, zawężając w ten sposób wykrywanie zmian do jednej ścieżki:
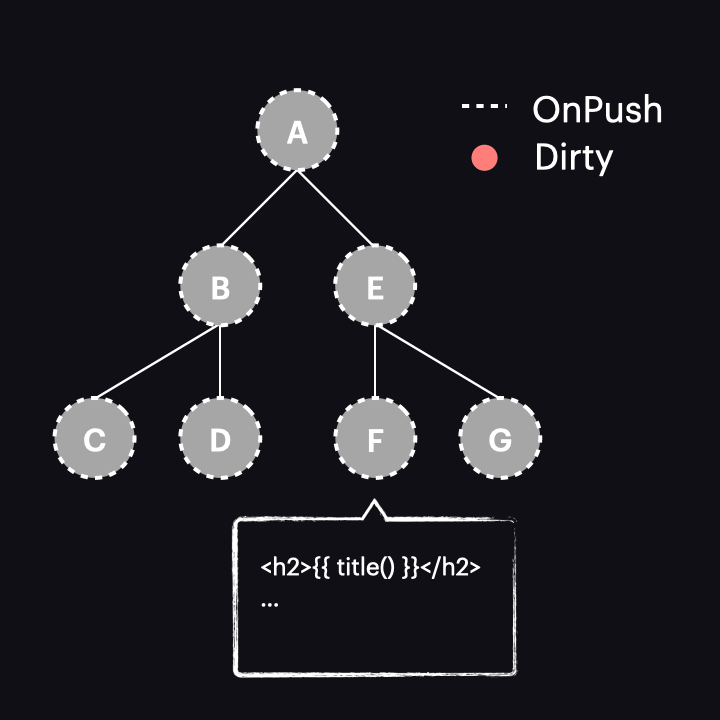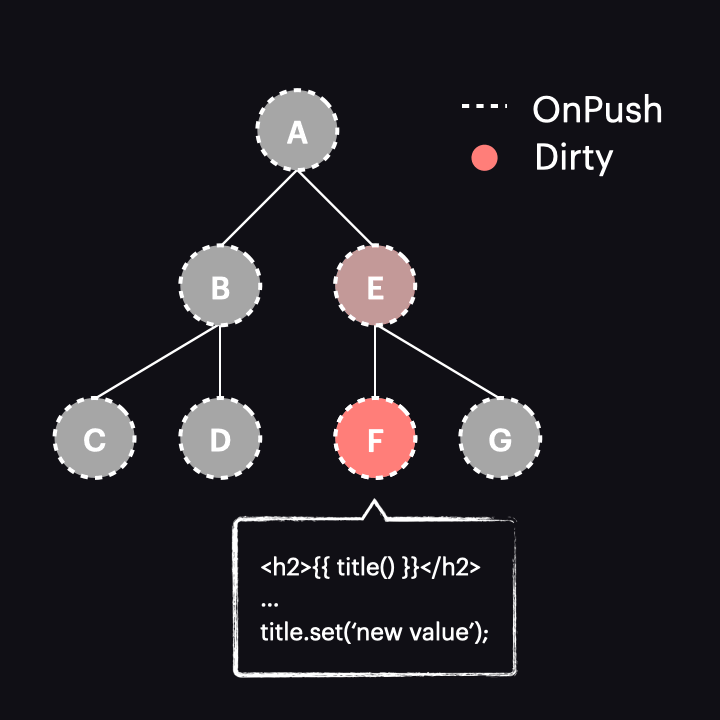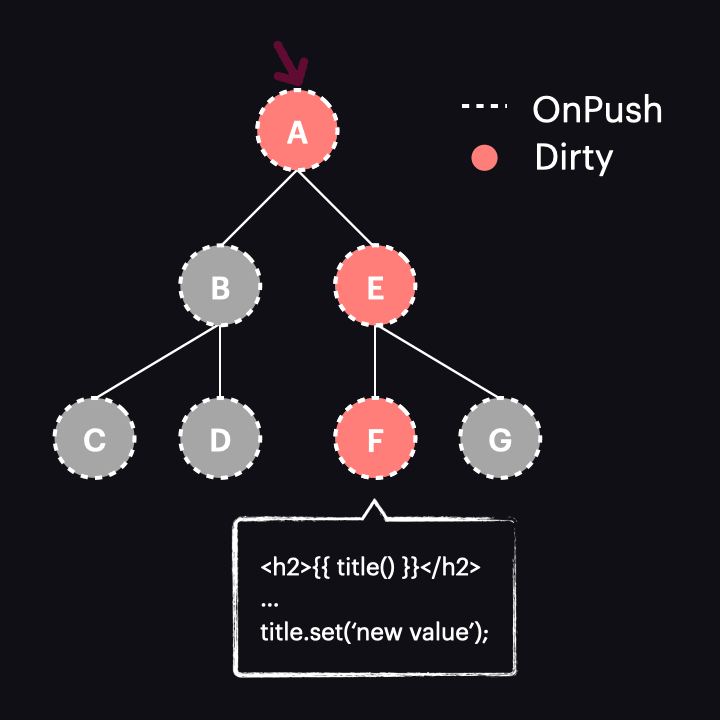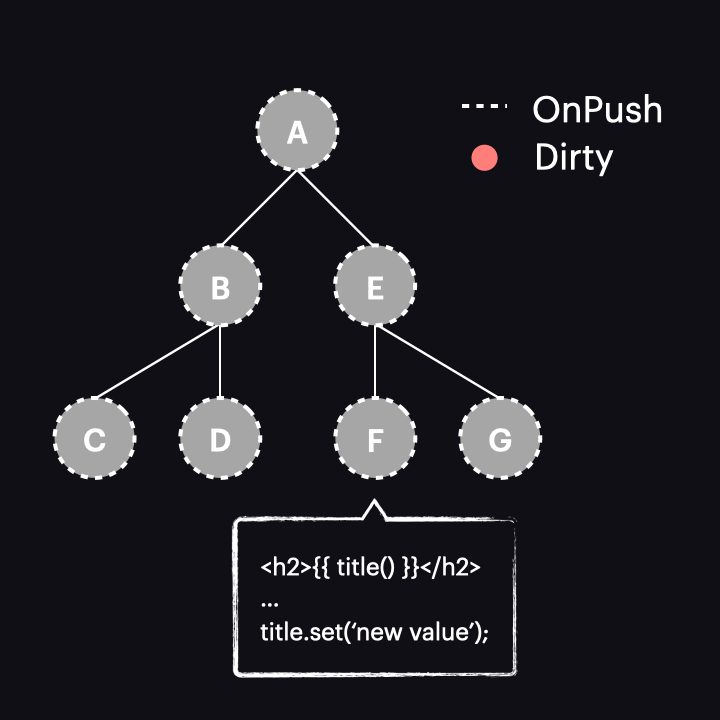
Jednak, jak właśnie odkryliśmy, działa dokładnie tak samo jak AsyncPipe, więc nie wydaje się, aby przynosiło to specjalne korzyści.
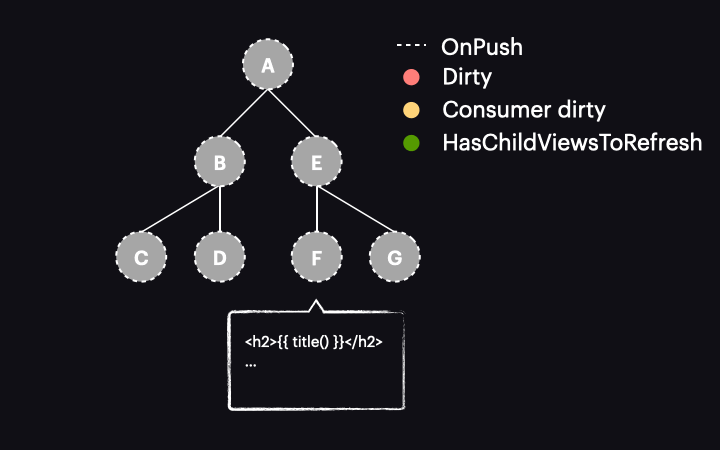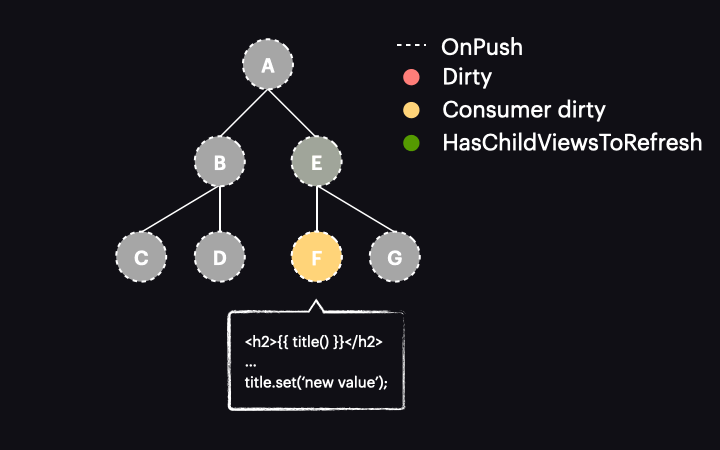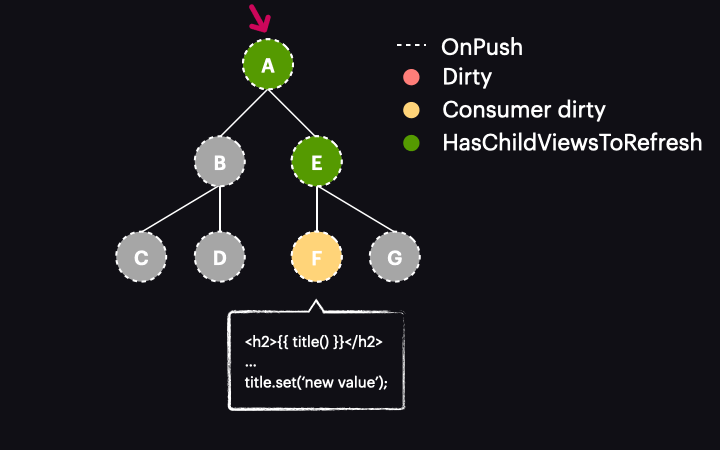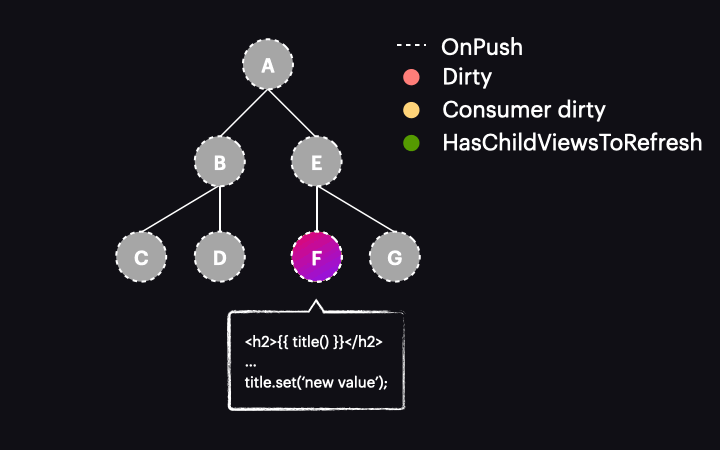
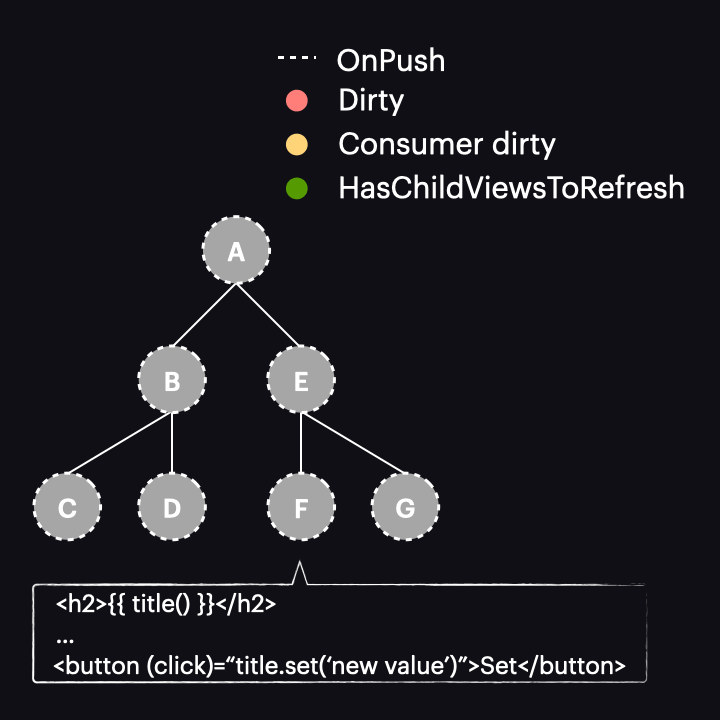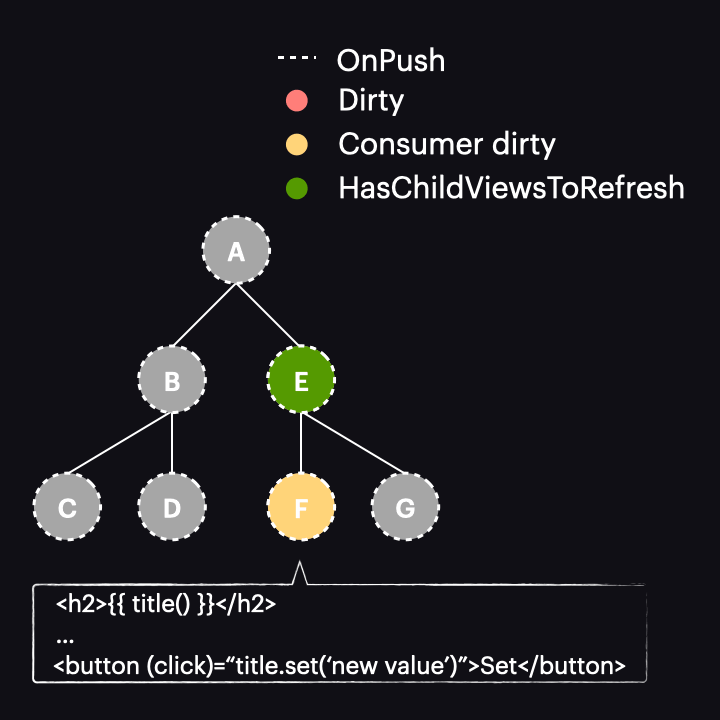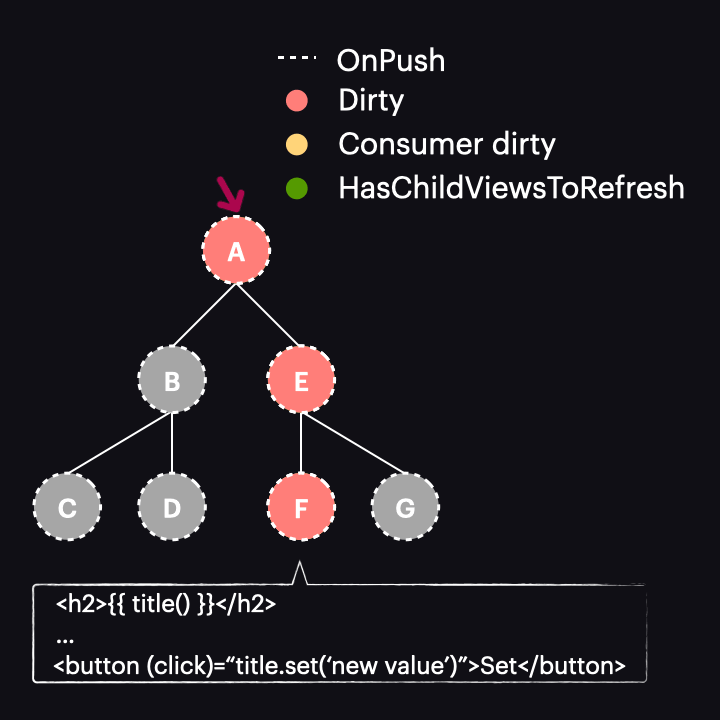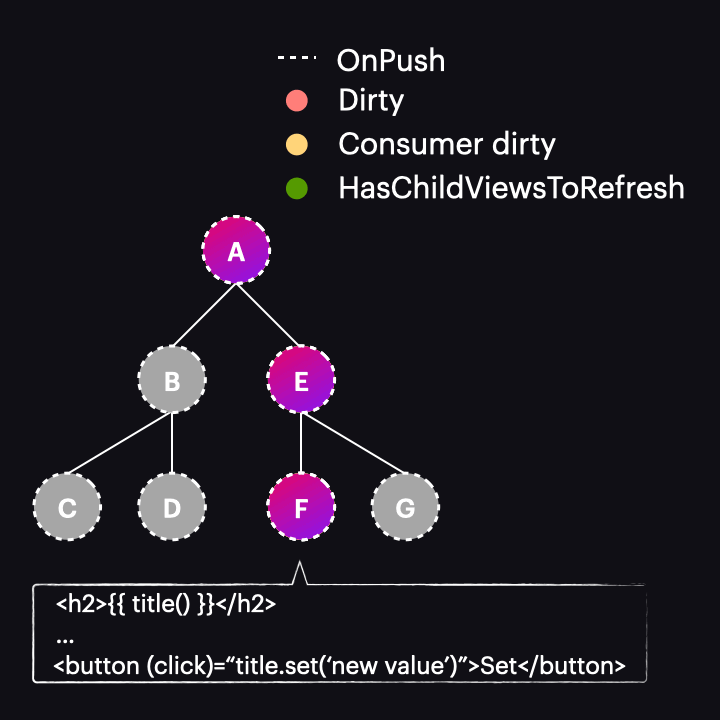
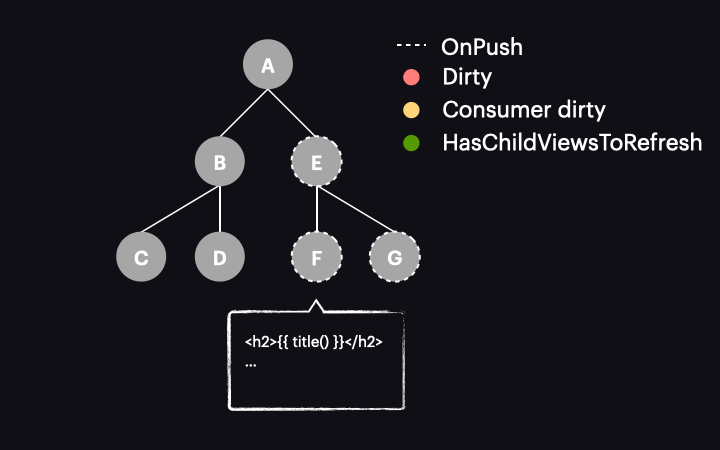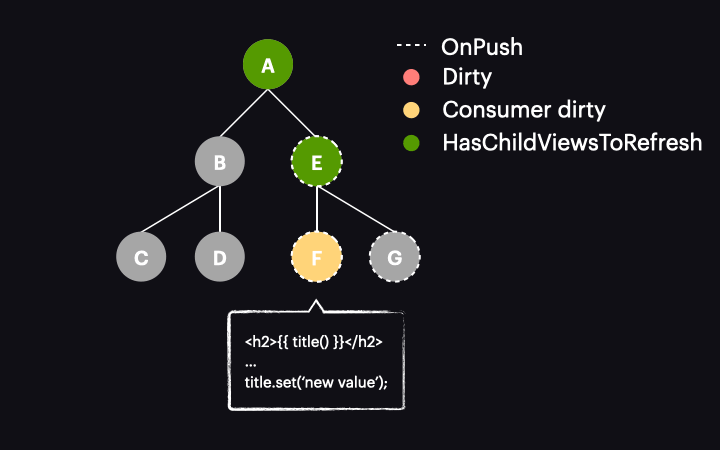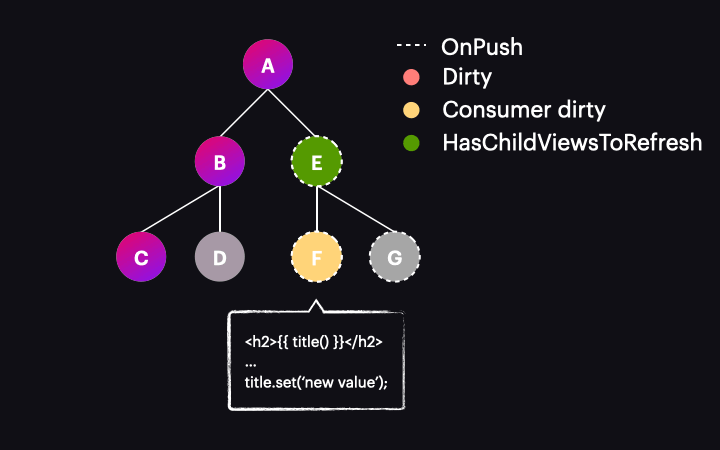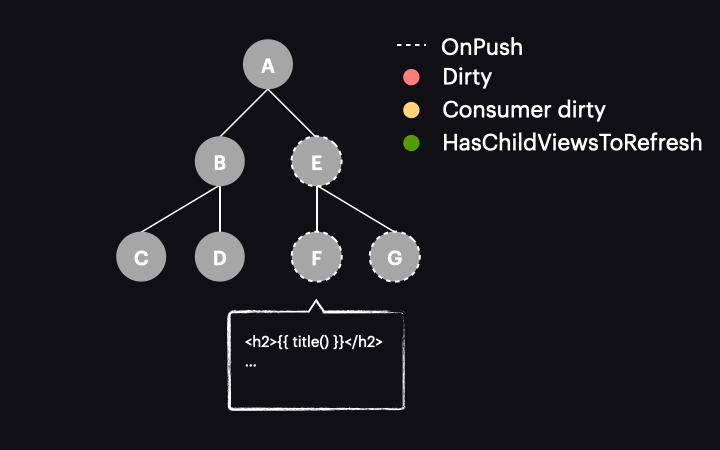
Sytuacja zmienia się diametralnie w przypadku Angulara 17 lub nowszego. W tych wersjach oznaczenie reaktywnego konsumenta jako dirty nie oznacza już całego komponentu jako dirty. Zamiast tego jest wywoływana nowa funkcja o nazwie markAncestorsForTraversal. Funkcja ta startuje z bieżącego komponentu i przechodzi przez jego przodków aż do root komponentu (podobnie jak robi to wspomniana już funkcja markViewDirty), ale zamiast oznaczać je jako dirty, pozostawia bieżący komponent bez zmian (ponieważ reaktywny konsument jest już oznaczony jako dirty). Jego przodkowie otrzymują natomiast oznaczenie nową flagą HasChildViewsToRefresh. Wygląda to tak:
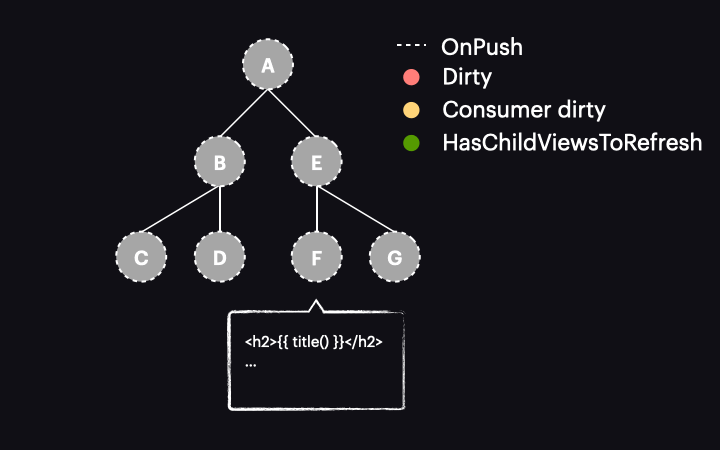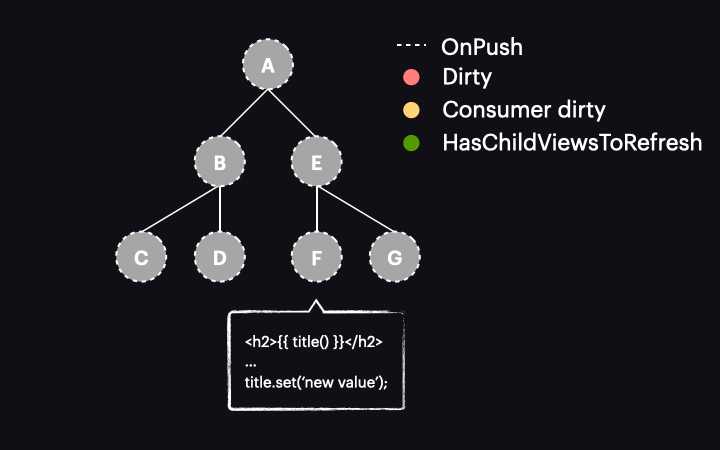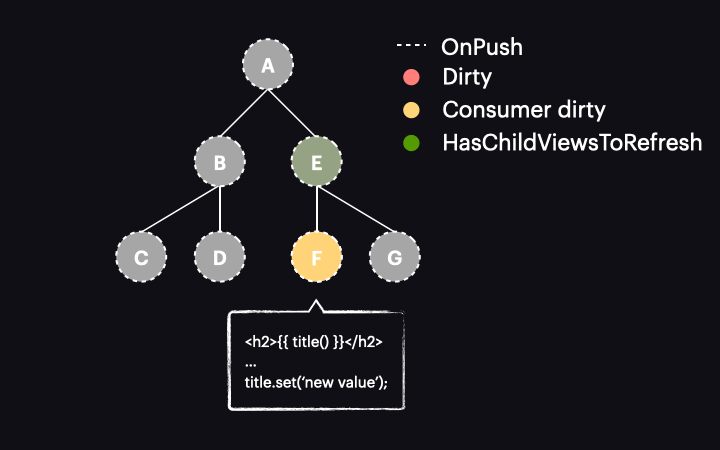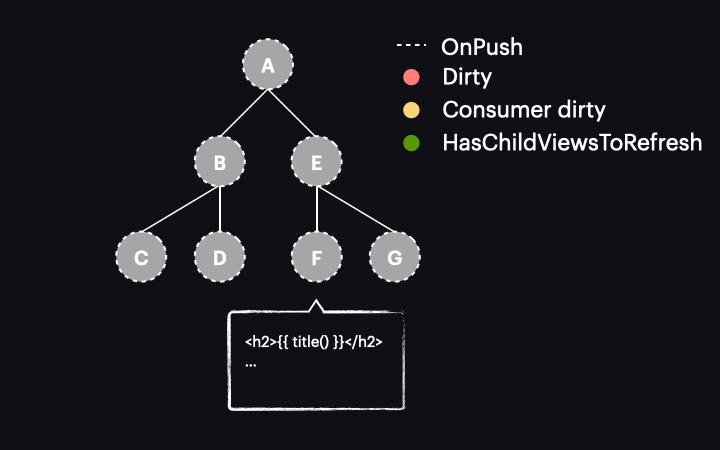
Sam mechanizm wykrywania zmian został także zmodyfikowany. Teraz, gdy proces rozpoczyna się z drzewem w stanie jak powyżej, proces przechodzi przez komponenty A i E, nie wykrywając w nich zmian. Dzieje się tak dlatego, że są typu OnPush, ale nie są dirty. Dzięki nowej fladze HasChildViewsToRefresh, Angular kontynuuje jednak odwiedzanie węzłów oznaczonych tą flagą i szuka komponentu wymagającego wykrycia zmian (w naszym przykładzie takiego, w którym konsument reaktywny jest oznaczony jako dirty). Kiedy dotrze do węzła komponentu F, stwierdza, że jego reaktywny konsument jest dirty, zatem dokonywana jest detekcja zmian w tym komponencie – i tylko w nim!
Całkiem cool, prawda? Przeszliśmy od wykonania detekcji zmian w całej ścieżce komponentów do tylko jednego komponentu. Chociaż jest to uproszczony przykład drzewa komponentów, wzrost wydajności w rzeczywistych zastosowaniach jest znacznie większy.
To nowe podejście do wykrywania zmian, w którym za pomocą sygnałów zawężamy operacje tylko do pojedynczego komponentu, jest często nazywane “semi-local change detection” lub “global-local/glocal change detection”.
Pułapki
Należy jednak wziąć pod uwagę pewne pułapki. Przeanalizujmy poniższy przykład, w którym kliknięcie użytkownika powoduje zmianę wartości sygnału:
Po kliknięciu przycisku zauważamy, że zamiast opisanego wcześniej scenariusza nasz komponent i wszyscy jego przodkowie zostają oznaczeni jako dirty, co skutkuje wykrywaniem zmian w nich wszystkich. Dlaczego tak się dzieje? Ma to miejsce dlatego, że nadal obowiązują istniejące od dawna zasady detekcji zmian. Czy pamiętasz wyzwalacze oznaczania komponentu jako dirty? Jednym z nich są zdarzenia zdefiniowane dla elementów w widoku i dokładnie to ma miejsce w tym przypadku. Jeśli zdebugujesz taki przykład, zobaczysz, że podczas gdy markAncestorsForTraversal jest rzeczywiście wywoływane, wołane jest jednak także markViewDirty.
Prowadzi to do wniosku, że źródło zmiany wartości sygnału ma duże znaczenie. Jeśli pochodzi od czegoś, co równocześnie oznacza komponent jako dirty, nie ma tu przewagi nad standardową strategią OnPush stosowaną na przykład w połączeniu z AsyncPipe. Aby skorzystać z semi-local change detection, wyzwalacz musi pochodzić z akcji, która nie oznacza komponentu jako dirty, ale mimo to powoduje zaplanowanie kolejnego przebiegu detekcji zmian. Przykłady obejmują:
setInterval,setTimeoutObservable.subscribe,toSignal(Observable), np. zawołanieHttpClient- RxJS
fromEvent,Renderer2.listen
Kolejną pułapką, która jest bardziej oczywista, ale nadal może zniweczyć nasze wysiłki, jest brak strategii OnPush dla niektórych komponentów aplikacji. Biorąc pod uwagę poniższe drzewo i zakładając, że wyzwalacz zmiany wartości sygnału nie oznacza komponentów jako dirty, poddrzewo ABCD będzie nadal podlegać wykrywaniu zmian wraz z naszym komponentem F zwyczajnie dlatego, że te komponenty nie korzystają z OnPush i będą sprawdzane pod kątem zmian podczas każdego uruchomienia, o ile tylko zostaną osiągnięte (strategia domyślna nadal ma do nich zastosowanie).
Optymalizacja „kiedy” – Zoneless
Właśnie sprawdziliśmy, jak sygnały znacząco poprawiły element „jak” procesu wykrywania zmian w Angularze. Przejdźmy teraz do drugiego aspektu: w jaki sposób można ulepszyć część „kiedy”? Okazuje się, że odpowiedzią zespołu Angular jest: Zoneless.
Po co pozbywać się Zone.js?
Na początek zastanówmy się, dlaczego w ogóle chcielibyśmy pozbyć się Zone.js. Jest ku temu kilka powodów:
- Zmniejszenie rozmiaru głównej paczki aplikacji (initial bundle size): Spójrz na te dwa rezultaty budowania (pierwszy z Zone.js, drugi bez). Jak widać, biblioteka Zone.js zajmuje około 30 kB w stanie nieskompresowanym i około 10 kB w formacie skompresowanym. To całkiem sporo jak na zależność, którą trzeba niezwłocznie załadować, zanim nasza aplikacja w ogóle wystartuje.
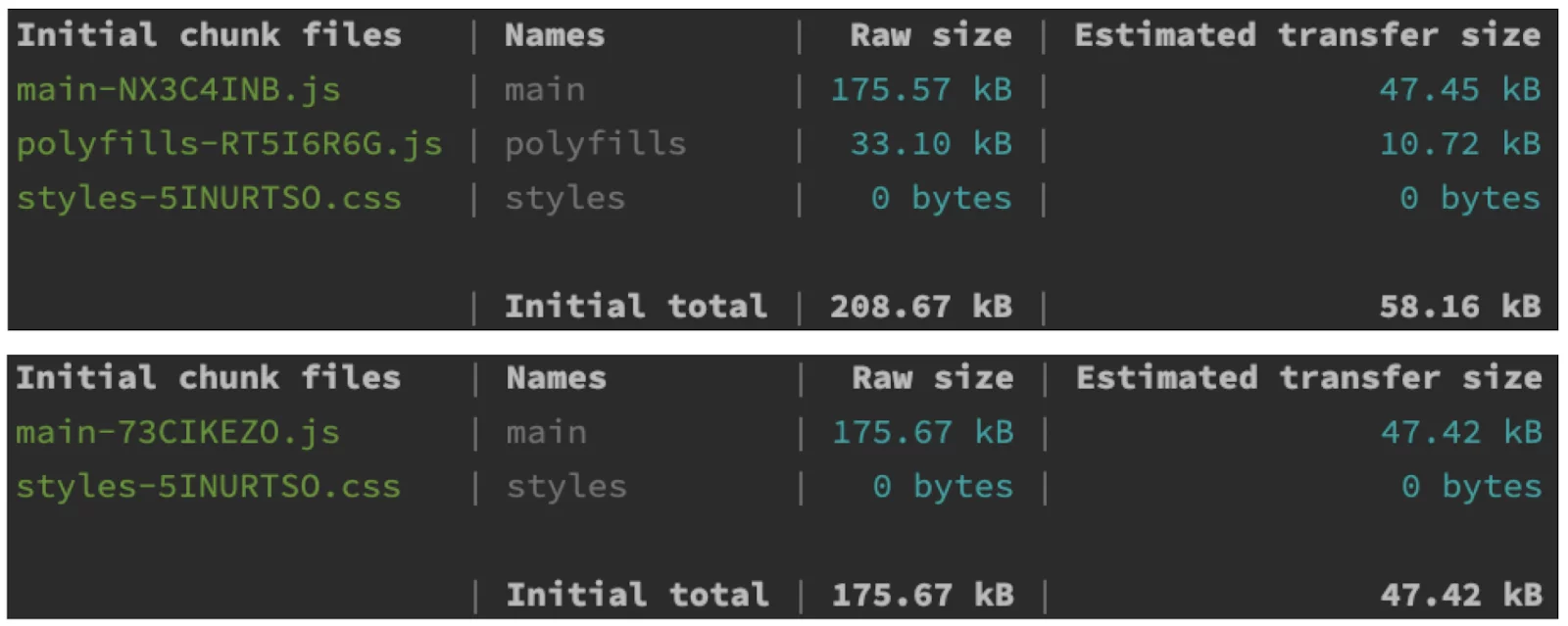
- Redukcja niepotrzebnych cykli wykrywania zmian: Zone.js pomaga Angularowi w wykrywaniu zmian, powiadamiając go o zakończeniu operacji, ale tak naprawdę nie wie, czy te operacje zmieniają jakiekolwiek dane. Z tego powodu framework ma tendencję do przesadnego reagowania, planując uruchomienie „na wszelki wypadek”.
- Poprawa debugowania: Obstawiam, że wielu z nas napotkało długie stosy wywołań (stack traces) podczas tworzenia aplikacji (zrzut ekranu poniżej pokazuje tylko około 20% stosu – i to tylko dla obsługi zdarzenia kliknięcia!).
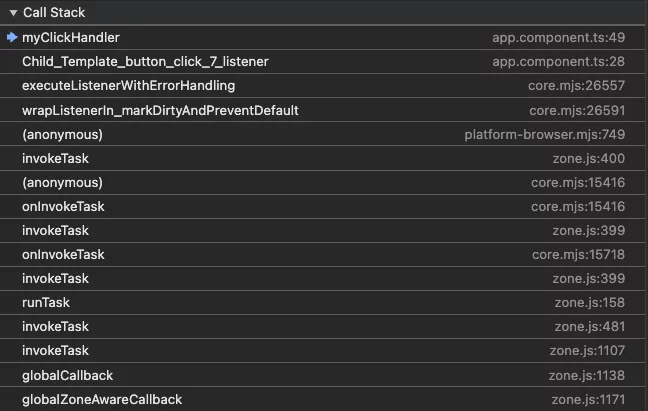
Mieszanka kodu Zone.js, frameworka i aplikacji nie jest zbyt czytelna i łatwa w obsłudze podczas debugowania. Mimo że Zespół Angular znacznie poprawił debugowanie w wersji 15, nadal miło jest móc całkowicie wyeliminować Zone.js.
- Przyspieszenie startu aplikacji: Oprócz konieczności bycia załadowanym przed uruchomieniem frameworka, Zone.js musi zostać również uruchomiony, aby zmodyfikować i móc przechwytywać wywołania różnych API przeglądarki. Pozbycie się tego może również zaoszczędzić nam trochę cennego czasu.
Nie zrozum mnie jednak źle – uważam, że Zone.js to ciekawe narzędzie (a przynajmniej takie było w momencie jego wprowadzenia), które od początku znacząco przyczyniło się do sukcesu Angulara. Ułatwia to pracę z frameworkiem nawet niedoświadczonym programistom – mogą po prostu skupić się na swoich zadaniach, a “magia” dzieje się sama.
Jednak, jak widzieliśmy, ta “magia” ma swoją cenę. Jestem pewien, że wiele, jeśli nie większość, aplikacji działa po prostu dobrze z Zone.js. Jednakże, poszukiwanie alternatyw jest logicznym krokiem w przypadku bardziej złożonych rozwiązań, które wymagają lepszej wydajności.
Jaka jest więc alternatywa dla Zone.js w Angularze? Cóż, skoro już wiemy, że to odpowiedzialność schedulera, aby uruchomiać wykrywanie zmian, nie jest niespodzianką, że dostaliśmy nowy scheduler.
Zoneless scheduler
Nowy scheduler, wprowadzony w wersji 17.1, odchodzi od polegania na zdarzeniach Zone.js i czeka na wyraźne powiadomienia o zmianach z innych części frameworka. Ten ruch ma bardzo duże znaczenie. Zamiast wyzwalać detekcję zmian, „gdy właśnie miała miejsce jakaś operacja i coś mogło się zmienić”, framework uruchamia ją teraz, „gdy otrzyma powiadomienie, że dane uległy zmianie”.
Aby to umożliwić, nowy scheduler udostępnia specjalną metodę notify, która jest wywoływana w następujących scenariuszach:
- Kiedy sygnał odczytany w widoku otrzyma nową wartość (a dokładnie kiedy
markAncestorsForTraversaljest wywoływane). - Gdy komponent zostanie oznaczony jako dirty poprzez funkcję
markViewDirty. Może się to zdarzyć między innymi z powodu nowej wartości otrzymanej przezAsyncPipe, zdarzenie zdefiniowane w widoku (event handler), wywołanieComponentRef.setInputczy wywołanieChangeDetectorRef.markForCheckwprost. - Kiedy
afterRenderhook zostanie zarejestrowany, widok zostanie ponownie dołączony do drzewa detekcji zmian lub usunięty ze struktury DOM. W tych przypadkach metodanotifyjest wywoływana, ale wykonuje tylko metody cyklu życia komponentu (lifecycle hooks) bez odświeżania widoku.
Możesz się zastanawiać, czy wykrywanie zmian nie będzie zatem działać zbyt często, na przykład gdy kilka sygnałów zmienia wartości lub gdy wiele zdarzeń następuje w krótkich odstępach czasu. Na szczęście implementacja schedulera została zaprojektowana tak, aby skutecznie sobie z tym radzić. Zbiera ona powiadomienia w krótkim oknie czasowym i planuje pojedyncze uruchomienie wykrywania zmian, zamiast uruchamiać je wielokrotnie. To zachowanie opiera się na implementacji wyścigu pomiędzy wywołaniem setTimeout i requestAnimationFrame ale nie będziemy tutaj zagłębiać się w dalsze szczegóły. Kluczowym wnioskiem jest to, że te zawołania notify są “łączone”, zapewniając optymalną wydajność.
Aby włączyć nowy scheduler, musisz zaktualizować aplikację w następujący sposób (kluczowym dodatkiem jest provideExperimentalZonelessChangeDetection, reszta zależy od istniejącej konfiguracji):
import {ApplicationConfig, provideExperimentalZonelessChangeDetection} from '@angular/core';
import {bootstrapApplication} from "@angular/platform-browser";
import {AppComponent} from "./app.component";
export const appConfig: ApplicationConfig = {
providers: [
provideExperimentalZonelessChangeDetection(),
]
};
bootstrapApplication(AppComponent, appConfig)
.catch((err) => console.error(err));
// usuń następujący kod z angular.json:
//
// "polyfills": [
// "zone.js"
// ],
Poniższa animacja ilustruje działanie nowego zoneless schedulera w aplikacji wykorzystującej OnPush i sygnały:
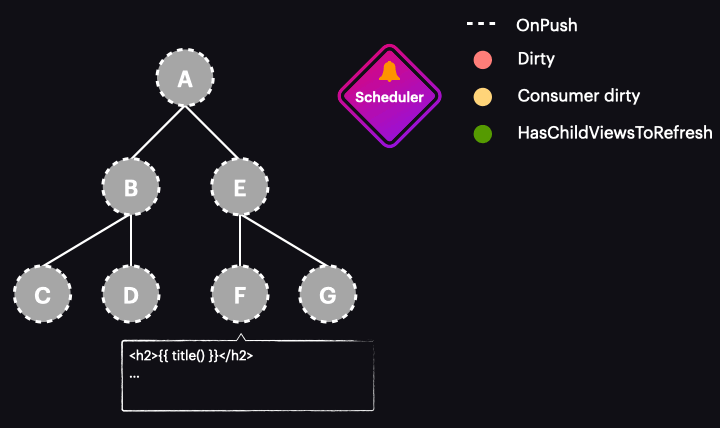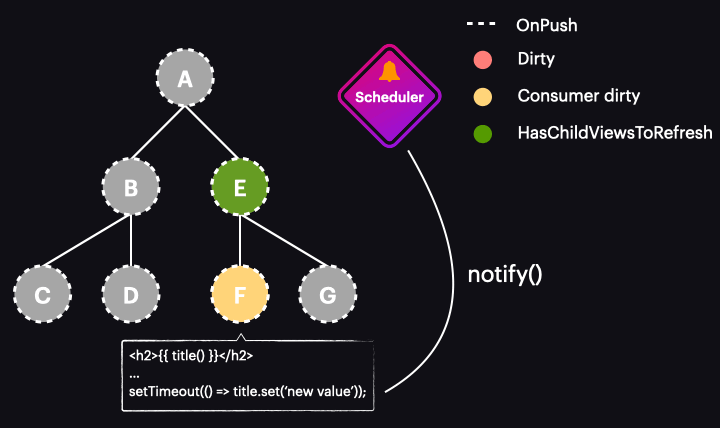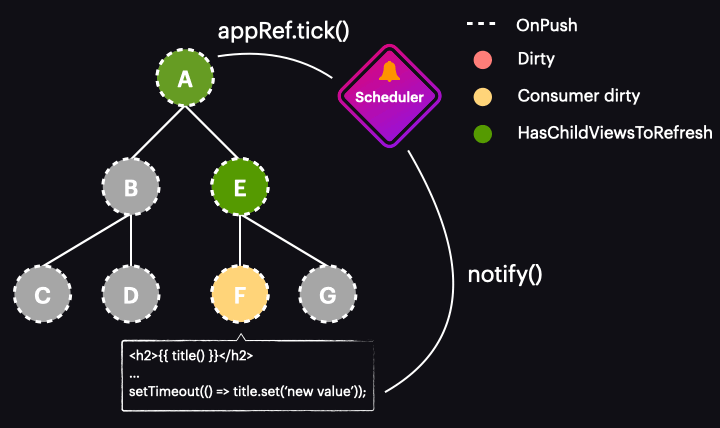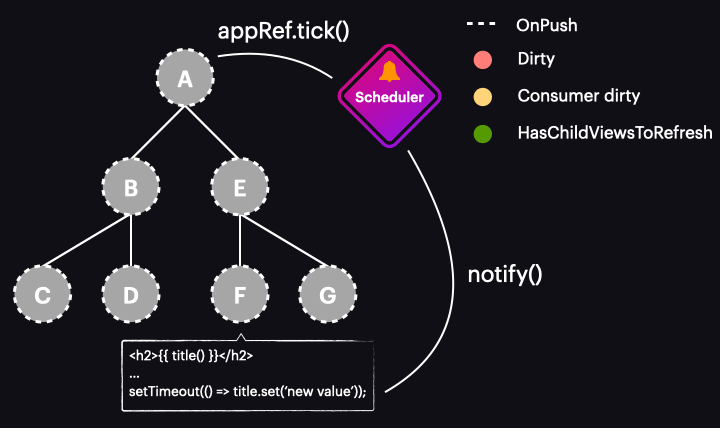
Oczywiście obrazuje ona najlepszy scenariusz, w którym zmiana wartości sygnału oznacza tylko pojedynczy komponent do wykrywania zmian i wyzwala cykl wykrywania zmian. Oznacza to, że wykrywamy zmiany tylko tam, gdzie jest to konieczne i dokładnie wtedy, gdy jest to potrzebne.
Ważnym spostrzeżeniem jest to, że nie musisz używać sygnałów, aby przejść na podejście Zoneless. Nowy harmonogram może reagować na różne typy powiadomień poza sygnałami (jak wspomniano wcześniej), dzięki czemu aplikacje intensywnie korzystające ze strategii OnPush również mogą skorzystać z tej możliwości.
Co lepsze, nie musisz od razu całkowicie przechodzić na podejście Zoneless. Nadal możesz osiągnąć lepszą wydajność, korzystając ze schedulera opartego na Zone.js.
Zonefull/hybrid scheduler
W poprzednim rozdziale zauważyliśmy, że Zoneless scheduler został po raz pierwszy wprowadzony w wersji 17.1. Angular 18 nie tylko znacznie poprawił tę implementację, ale także wprowadził bardzo ciekawe ulepszenie istniejącego schedulera opartego na Zone.js, włączając do niego mechanizm jawnego powiadamiania, który widzieliśmy już w Zoneless schedulerze. Oznacza to, że scheduler nasłuchuje teraz nie tylko na zdarzenia Zone.js, ale jest także wyzwalany przez metodę notify.
Przed Angularem 18, jeśli wartość sygnału zmieniła się poza widocznością Zone.js, cykl detekcji zmian nie byłby zaplanowany – tylko operacje wykonane w ramach zone gwarantowałyby planowanie. Rozważmy na przykład następujący kod, który do tej pory nie spowodowałby odświeżenia widoku:
zone.runOutsideAngular(() => {
httpClient.get<Post>('https://jsonplaceholder.typicode.com/posts/1')
.pipe(
delay(3000),
map((res) => res.title)
).subscribe((title) => {
this.title.set(title);
});
});
Dzięki uplepszonemu, hybrydowemu schedulerowi, nadal możemy osiągnąć odświeżenie widoku w tym samym scenariuszu. Dzieje się tak, ponieważ zmiana wartości sygnału wywołuje notify i nie ma już znaczenia, czy jesteśmy w obszarze wykrywalności przez Zone.js, czy poza.
Otwiera to wiele nowych możliwości dla aplikacji, które nie są jeszcze gotowe na pracę w trybie Zoneless, ale nadal mogą czerpać korzyści podczas stopniowej adaptacji.
Podsumowanie
Mam nadzieję, że ten artykuł pomógł Ci zrozumieć postępy w mechanizmach wykrywania zmian w Angularze oraz wyjaśnił, jak te koncepcje mogą współdziałać. Byłbym również zadowolony, gdyby jednym z Twoich głównych wniosków było, że nie musisz od razu „iść na całość” w kwestii tych zmian. Jeśli to powstrzymuje Cię przed korzystaniem z najnowszych funkcji, pamiętaj, że możesz stopniowo dostosowywać swoją aplikację. Z czasem możesz wykorzystywać coraz więcej sygnałów, zapewniać kompatybilność kolejnych komponentów ze strategią OnPush i ostatecznie przejść na podejście Zoneless. W międzyczasie nadal będziesz czerpać korzyści.